Business Strategy
AI ROI Calculator for Small Business: Complete Implementation Guide 2025
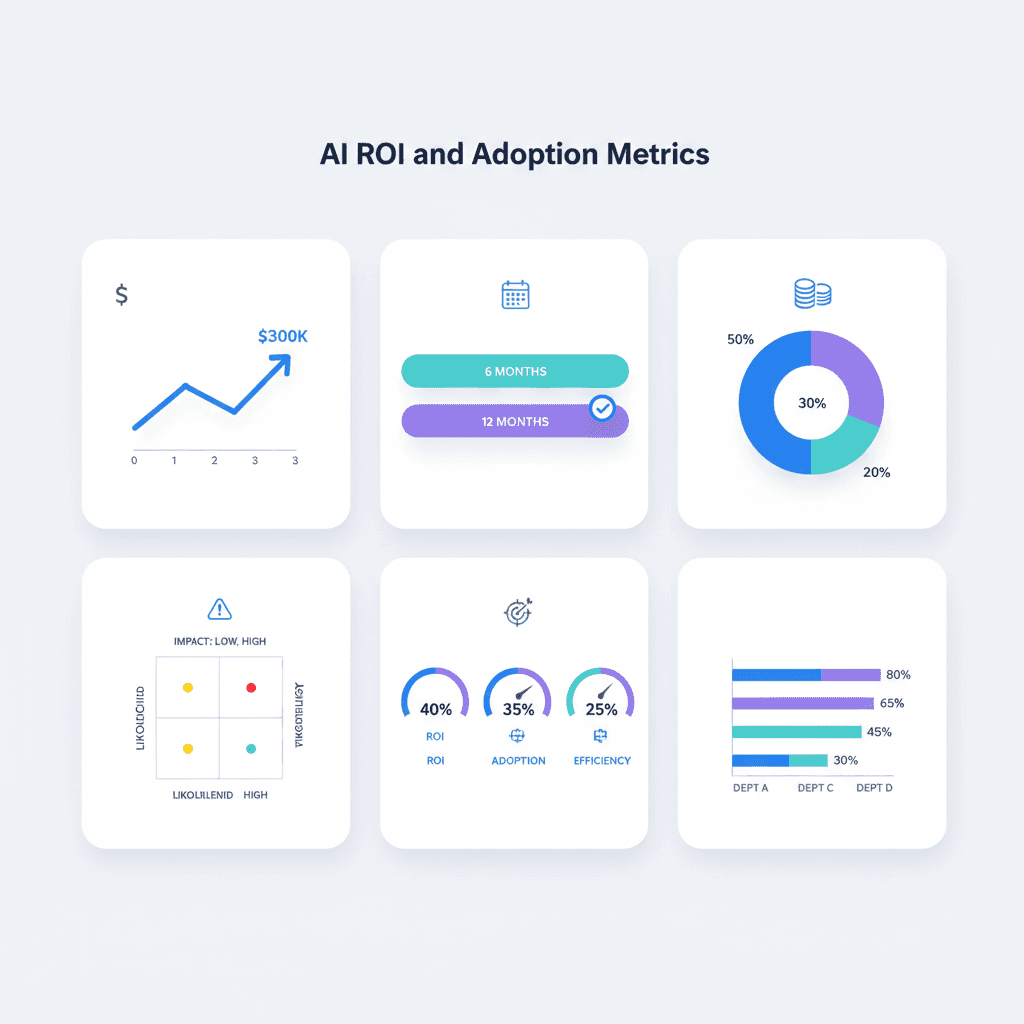
Calculate AI ROI for your small business with our proven framework. Step-by-step guide includes cost breakdown, payback period, and real implementation examples.
•9 min read
