
AI in Production
AgentOps Production Implementation Guide 2026
Build production AgentOps pipelines: agent versioning, multi-agent debugging, cost tracking, A/B testing autonomous systems with full code examples.
•19 min read
Deep dives into AI engineering, production deployment, MLOps, and modern machine learning practices.
Showing 1-9 of 84 articles
Build production AgentOps pipelines: agent versioning, multi-agent debugging, cost tracking, A/B testing autonomous systems with full code examples.

Build production real-time ML feature pipelines with Kafka and Flink. Achieve sub-40ms latency, solve training-serving skew, and deploy streaming feature stores at scale.

IBM Docling v2.72.0 production deployment with Granite-Docling-258M. 97.9% table accuracy, Celery async processing, OCR config, RAG pipelines. Complete guide.

Anthropic Claude Cowork autonomous agent for non-coding work. Production deployment, 11 plugins, legal/finance/sales automation. macOS guide with security patterns.
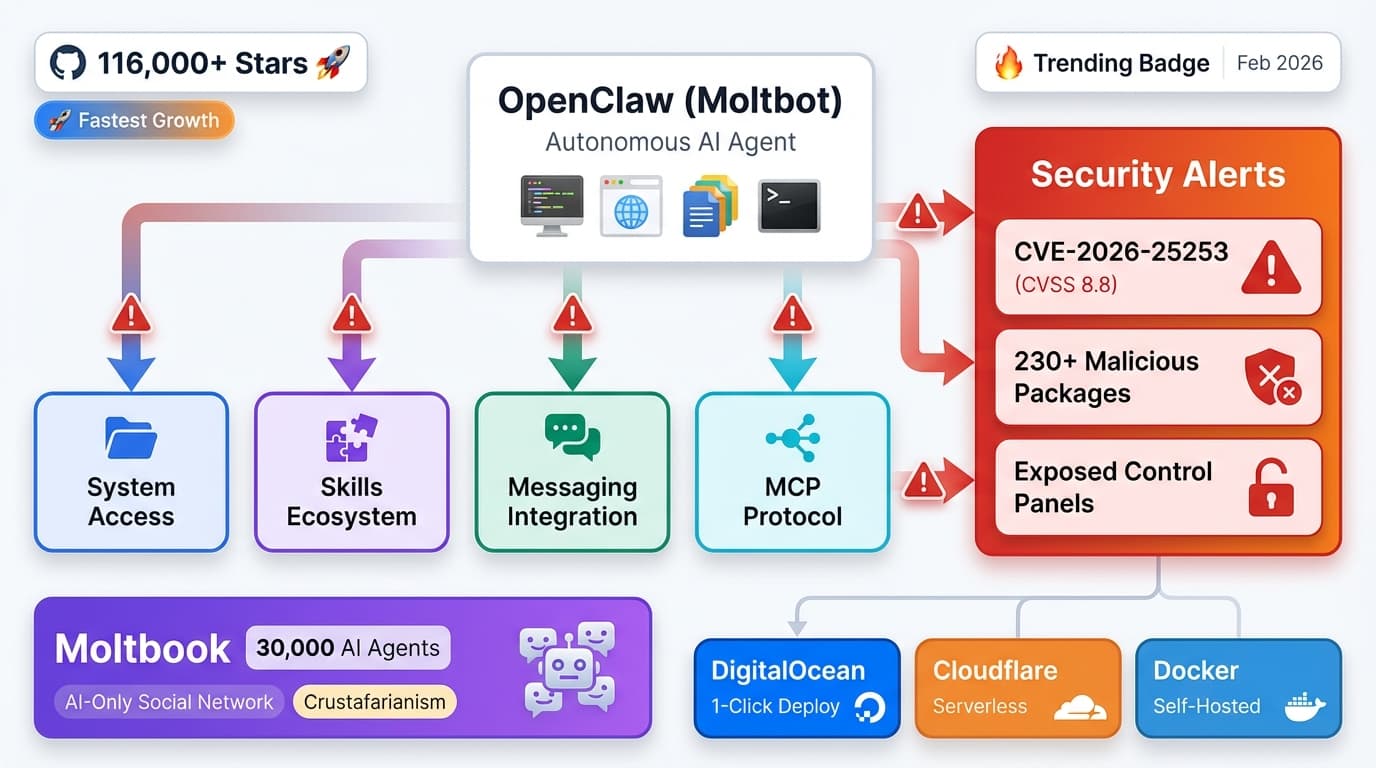
OpenClaw (Moltbot) hits 116K GitHub stars. Autonomous AI agent controls computers. Production deployment, security risks, Moltbook AI social network guide.
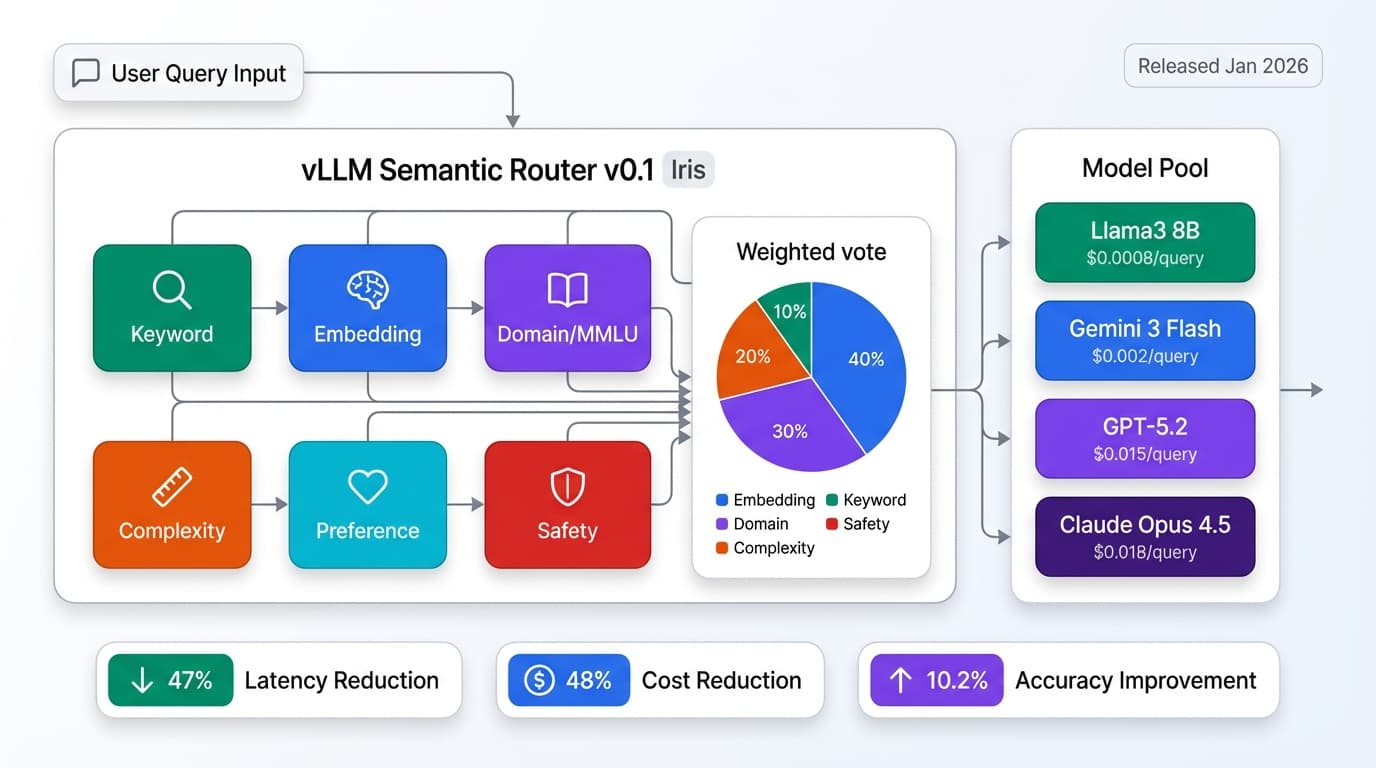
vLLM Semantic Router v0.1 cuts costs 48% and latency 47%. Production deployment guide: model routing, safety filtering, semantic caching with Kubernetes.
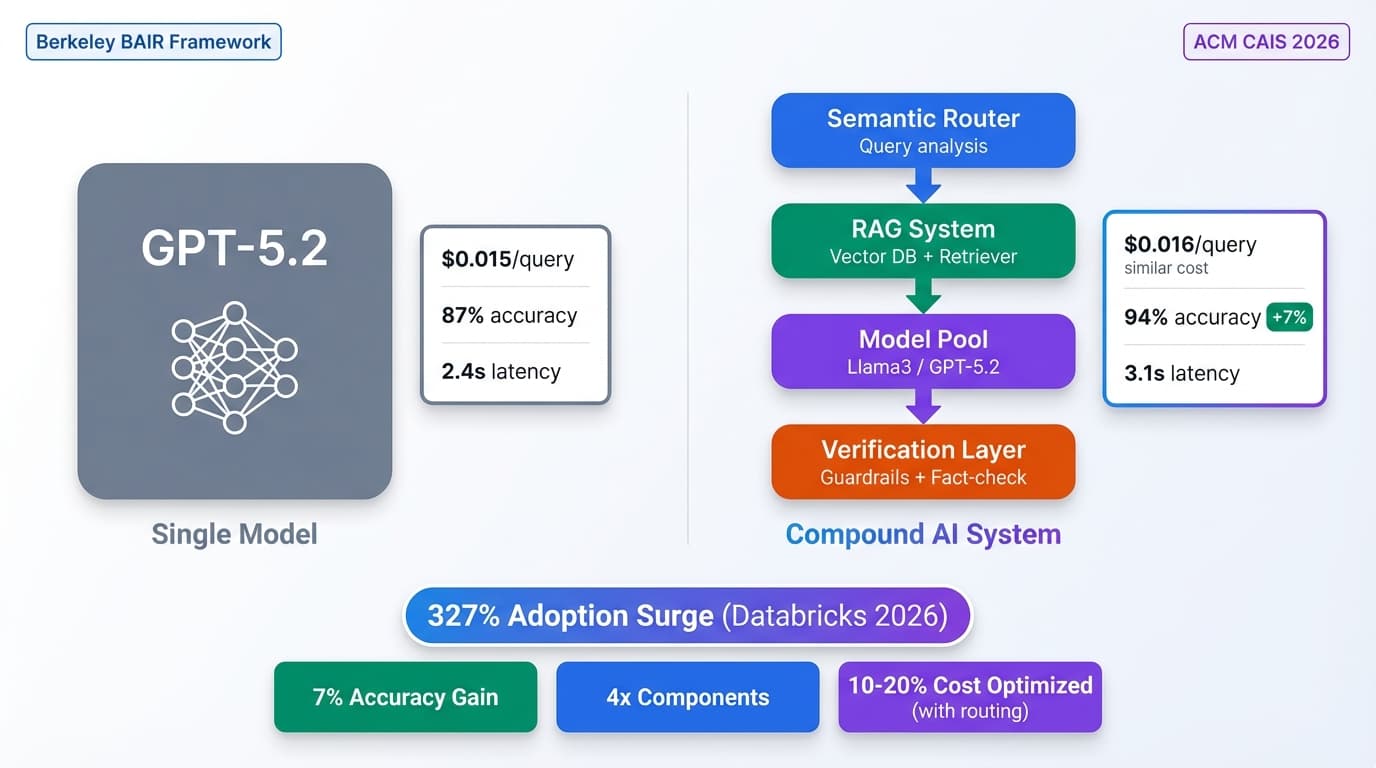
Databricks 327% surge. Compound AI beats single models. Production guide: RAG, routing, guardrails, agents. Berkeley BAIR framework patterns.
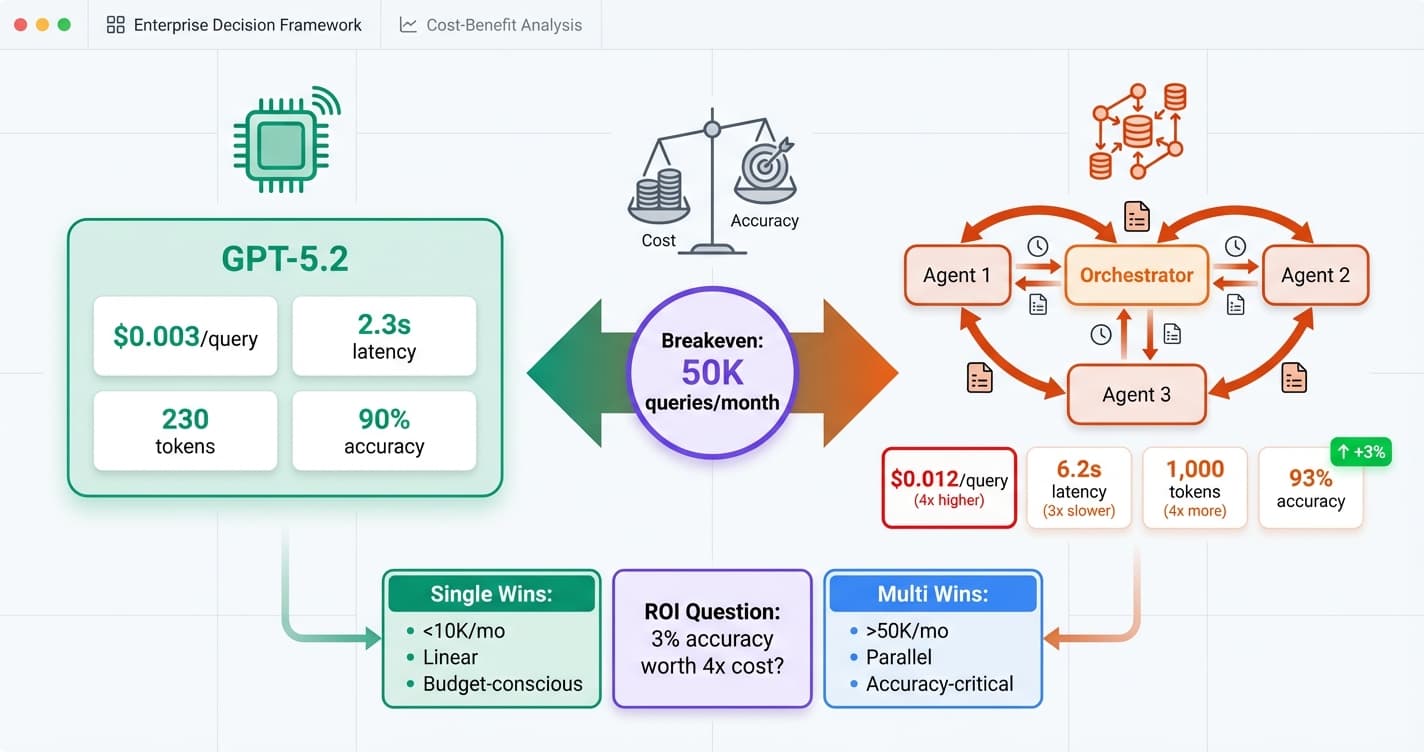
327% growth in multi-agent systems but are they worth it? Cost breakeven analysis, single vs multi-agent ROI comparison, decision framework for CTOs.

Claude Sonnet 4.5 wins: 9.2/10 quality at $0.08/task (3x cheaper than Codex). 500-task production benchmark with cost analysis and language tests.