
AI in Production
LLM Inference Optimization Production Guide 2026
Reduce LLM inference costs by 10x and improve latency 5x. Complete guide to vLLM, continuous batching, KV-cache optimization, speculative decoding with production code.
•18 min read
Deep dives into AI engineering, production deployment, MLOps, and modern machine learning practices.
Showing 19-27 of 84 articles
Reduce LLM inference costs by 10x and improve latency 5x. Complete guide to vLLM, continuous batching, KV-cache optimization, speculative decoding with production code.

Build production AI guardrails that catch 95% of safety issues. Complete guide to input validation, output filtering, NeMo Guardrails, compliance with production code.

Complete guide to building AI-powered semantic search with RAG. Hybrid retrieval, embedding models, production architecture. Includes 200+ lines of production code and real implementation lessons.

Learn how AI transforms legal workflows with contract review automation, due diligence, and risk analysis. 54% adoption rate, 40% faster cycle times. Implementation guide with production code.

Master real-time LLM streaming 2026: sub-100ms latency with vLLM, FastAPI streaming endpoints, PagedAttention, continuous batching reducing costs 40%.

Master RAG embeddings and reranking with Qwen3, ModernBERT, and Cohere to achieve 35% accuracy improvements. Complete 2026 production guide with code.

Cut LLM costs 50% with batch inference. Production guide covering continuous batching, vLLM, OpenAI Batch API, AWS Bedrock 2.9x cost reduction.

Master LLM testing in production 2026: pytest frameworks for non-deterministic outputs, semantic evaluation metrics, continuous testing pipelines reducing failures 65%.
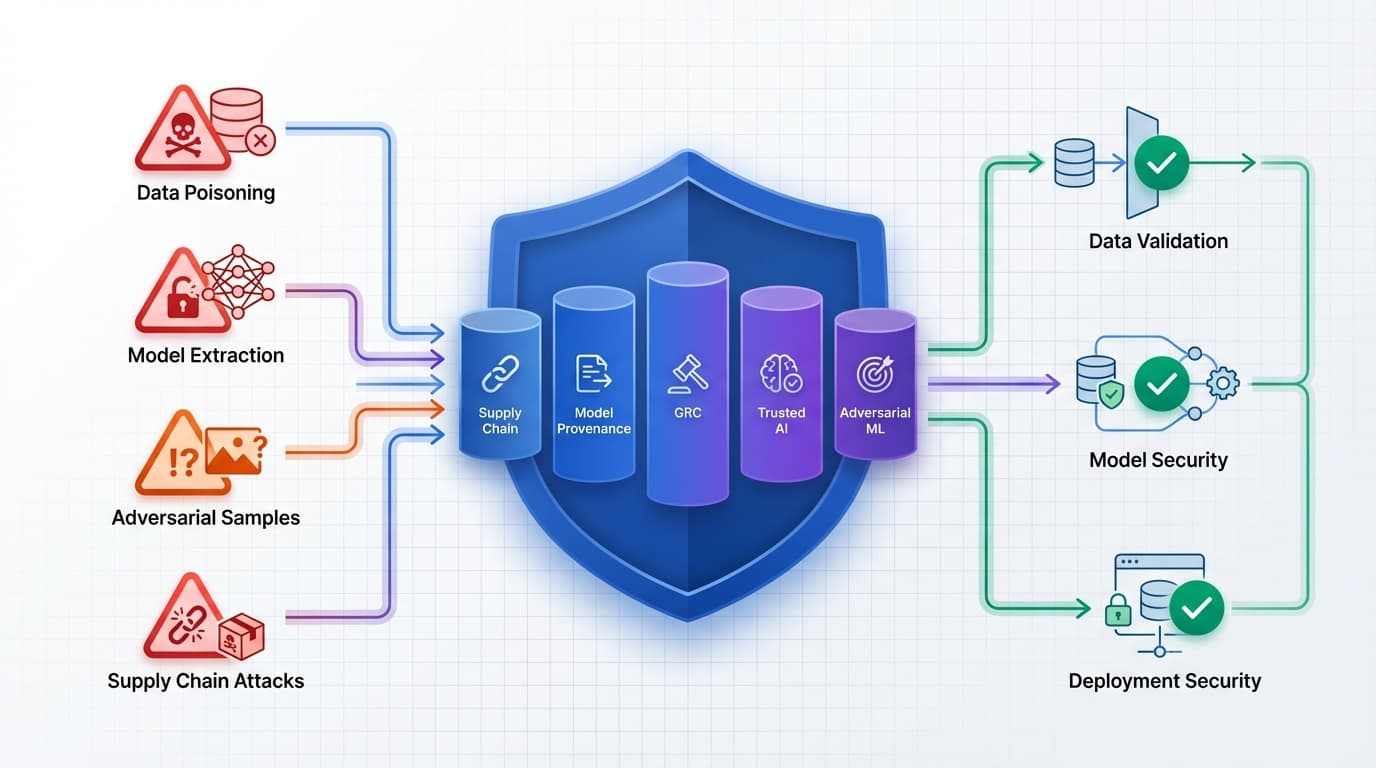
MLSecOps guide 2026: Secure ML pipelines with OWASP LLM Top 10, data poisoning defense, model extraction prevention, and agentic AI security patterns.