Real-Time Streaming LLM Inference Guide 2026
Master real-time LLM streaming 2026: sub-100ms latency with vLLM, FastAPI streaming endpoints, PagedAttention, continuous batching reducing costs 40%.
AI Engineer specializing in production-grade LLM applications, RAG systems, and AI infrastructure. Passionate about building scalable AI solutions that solve real-world problems.
ChatGPT feels instant. Your LLM app doesn't. The difference? ChatGPT streams first tokens in 80ms. Most custom apps wait 3-5 seconds for the complete response, then display it all at once. To users, this feels sluggish and unresponsive. Human perception research shows 200ms feels instant, 1 second feels slow, and 3+ seconds causes abandonment.
According to Google's 2025 research, 53% of users abandon applications if responses take longer than 3 seconds. OpenAI's UX research found streaming improves perceived speed by 70% compared to batch responses. Meanwhile, vLLM achieves 23x throughput versus naive PyTorch implementations through continuous batching and PagedAttention.
This guide covers production-ready streaming implementations using FastAPI + vLLM, optimization strategies for sub-100ms Time To First Token (TTFT), and infrastructure patterns for serving thousands of concurrent requests. By the end, you'll understand how to build real-time LLM applications that feel as responsive as ChatGPT.
Understanding Latency Bottlenecks in LLM Inference
Before optimizing, identify where latency comes from. LLM inference has five critical bottlenecks, each requiring different solutions:
Cold Start Latency (2-5 seconds) occurs when loading models from disk into GPU memory. A 7B parameter model with FP16 precision requires 14GB VRAM and takes 2-5 seconds to load. Solution: Keep models loaded (warm) in GPU memory 24/7. Use health check endpoints that return instantly if the model is ready. Only acceptable during initial deployment or scaling events.
Time To First Token - TTFT (200-1000ms) represents the prefill phase where the model processes the entire prompt at once to generate KV cache states. A 200-token prompt on Llama-2-7B takes 500ms-1s depending on GPU. This is fundamentally sequential and can't be parallelized. Solution: Shorter prompts, prompt caching for repeated prefixes (system prompts), FP16 quantization, and continuous batching to amortize prefill costs.
Inter-Token Latency (15-50ms per token) measures time between generated tokens. Each token requires a forward pass through the model. With 50 tokens/sec generation speed, that's 20ms per token. This multiplies: generating 100 tokens takes 2 seconds at 20ms/token. Solution: Model quantization (FP16→INT8), speculative decoding, and tensor parallelism across multiple GPUs.
Network Overhead (50-150ms) includes API round-trip time, TLS handshake, request/response serialization, and cloud network latency. For edge-to-cloud architectures, add 20-100ms each direction. Solution: Server-Sent Events (SSE) for streaming (avoids multiple HTTP requests), gRPC for binary protocol efficiency, edge deployment to reduce network hops.
GPU Memory Bottleneck occurs when KV cache grows linearly with sequence length. A 2K token conversation with batch size 32 requires 2GB+ KV cache, fragmenting GPU memory and causing Out of Memory (OOM) errors. Solution: PagedAttention (vLLM's breakthrough), prompt caching, sequence length limits.
Latency Breakdown Example:
- Baseline: Cold Start (0ms, model preloaded) + TTFT (200ms) + Inter-Token (100 tokens × 20ms) + Network (50ms) = 2,250ms total
- Optimized: Cold Start (0ms) + TTFT (80ms, prompt caching) + Inter-Token (100 tokens × 15ms, FP16 quantization) + Network (30ms, SSE streaming) = 1,610ms total (28% improvement)
The key insight: optimize TTFT and inter-token latency first, as they dominate total latency. Network and cold start are secondary. For comprehensive quantization strategies, see our deployment guide.
Production Streaming API with FastAPI + vLLM
Here's a production-ready FastAPI streaming endpoint using vLLM's optimized inference engine. This implementation handles concurrent requests, streams tokens via Server-Sent Events (SSE), includes error handling, and tracks latency metrics. Copy-paste and adapt to your models.
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from pydantic import BaseModel, Field
from typing import Optional, AsyncGenerator
import asyncio
import time
from vllm import AsyncLLMEngine, SamplingParams, AsyncEngineArgs
from vllm.utils import random_uuid
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Initialize FastAPI app
app = FastAPI(title="Streaming LLM API", version="1.0.0")
# Global engine instance (initialized on startup)
engine: Optional[AsyncLLMEngine] = None
# Request/Response models
class CompletionRequest(BaseModel):
"""Completion API request schema"""
prompt: str = Field(..., min_length=1, max_length=4000,
description="Input prompt (max 4000 chars)")
max_tokens: int = Field(default=512, ge=1, le=2048,
description="Maximum tokens to generate")
temperature: float = Field(default=0.7, ge=0.0, le=2.0,
description="Sampling temperature")
top_p: float = Field(default=0.9, ge=0.0, le=1.0,
description="Nucleus sampling threshold")
stream: bool = Field(default=True,
description="Enable streaming response")
class CompletionChunk(BaseModel):
"""SSE streaming chunk format"""
id: str
text: str
finish_reason: Optional[str] = None
usage: Optional[dict] = None
# vLLM Engine Configuration
@app.on_event("startup")
async def initialize_engine():
"""Initialize vLLM engine on server startup"""
global engine
logger.info("Initializing vLLM AsyncLLMEngine...")
engine_args = AsyncEngineArgs(
model="meta-llama/Llama-2-7b-chat-hf", # HuggingFace model name
tensor_parallel_size=1, # Single GPU (use 2+ for 70B models)
dtype="float16", # FP16 for 2x speedup (vs FP32)
gpu_memory_utilization=0.9, # Use 90% of GPU memory
max_num_batched_tokens=8192, # Continuous batching buffer
max_num_seqs=64, # Max concurrent sequences in batch
enable_prefix_caching=True, # Cache repeated prompt prefixes
disable_log_stats=False, # Enable performance logging
# Optional: quantization for further speedup
# quantization="awq", # or "gptq", "fp8"
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
logger.info("vLLM engine initialized successfully")
@app.on_event("shutdown")
async def shutdown_engine():
"""Cleanup on server shutdown"""
global engine
if engine:
# vLLM handles cleanup automatically
logger.info("Shutting down vLLM engine")
# Health check endpoint
@app.get("/health")
async def health_check():
"""Health check - returns instantly if model is loaded"""
if engine is None:
raise HTTPException(status_code=503,
detail="Engine not initialized")
return {"status": "healthy", "model": "Llama-2-7b-chat"}
# Metrics tracking
class LatencyMetrics:
"""Track TTFT and inter-token latency"""
def __init__(self):
self.request_start = time.time()
self.first_token_time = None
self.token_count = 0
self.last_token_time = None
def record_first_token(self):
if self.first_token_time is None:
self.first_token_time = time.time()
def record_token(self):
self.token_count += 1
self.last_token_time = time.time()
def get_metrics(self):
if self.first_token_time is None:
return None
ttft = self.first_token_time - self.request_start
total_time = self.last_token_time - self.request_start
inter_token = (total_time - ttft) / max(self.token_count - 1, 1)
return {
"ttft_ms": round(ttft * 1000, 2),
"inter_token_ms": round(inter_token * 1000, 2),
"total_time_ms": round(total_time * 1000, 2),
"tokens_generated": self.token_count,
"tokens_per_second": round(self.token_count / total_time, 2)
}
# Streaming generator
async def stream_completion(
prompt: str,
sampling_params: SamplingParams,
request_id: str
) -> AsyncGenerator[str, None]:
"""
Stream tokens as Server-Sent Events (SSE)
Yields: data: {json}\n\n for each token
"""
metrics = LatencyMetrics()
try:
# Add request to vLLM engine queue
results_generator = engine.generate(
prompt,
sampling_params,
request_id
)
# Stream tokens as they're generated
async for request_output in results_generator:
# Extract generated text
text = request_output.outputs[0].text
# Track metrics
if not text: # Skip empty first output
continue
metrics.record_first_token()
metrics.record_token()
# Check for completion
finish_reason = request_output.outputs[0].finish_reason
# Create SSE chunk
chunk = CompletionChunk(
id=request_id,
text=text,
finish_reason=finish_reason
)
# Yield as SSE format: "data: {json}\n\n"
yield f"data: {chunk.json()}\n\n"
# Break if generation finished
if finish_reason is not None:
break
# Send final chunk with usage metrics
final_metrics = metrics.get_metrics()
if final_metrics:
final_chunk = CompletionChunk(
id=request_id,
text="",
finish_reason="stop",
usage=final_metrics
)
yield f"data: {final_chunk.json()}\n\n"
# Log metrics
logger.info(
f"Request {request_id}: TTFT={final_metrics['ttft_ms']}ms, "
f"Inter-token={final_metrics['inter_token_ms']}ms, "
f"Total={final_metrics['total_time_ms']}ms, "
f"Tokens={final_metrics['tokens_generated']}"
)
except asyncio.CancelledError:
# Client disconnected - cancel generation
logger.info(f"Request {request_id} cancelled by client")
await engine.abort(request_id)
raise
except Exception as e:
logger.error(f"Error in request {request_id}: {str(e)}")
error_chunk = CompletionChunk(
id=request_id,
text="",
finish_reason="error"
)
yield f"data: {error_chunk.json()}\n\n"
# Main completion endpoint
@app.post("/v1/completions")
async def create_completion(request: CompletionRequest):
"""
Generate completion with streaming support
Returns: StreamingResponse (SSE) if stream=True, else JSON
"""
if engine is None:
raise HTTPException(status_code=503,
detail="Engine not initialized")
# Generate unique request ID
request_id = random_uuid()
# Configure sampling parameters
sampling_params = SamplingParams(
temperature=request.temperature,
top_p=request.top_p,
max_tokens=request.max_tokens,
stop=[], # Add stop sequences if needed
)
# Return streaming response
if request.stream:
return StreamingResponse(
stream_completion(request.prompt, sampling_params, request_id),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Request-ID": request_id
}
)
else:
# Non-streaming response (for backwards compatibility)
results_generator = engine.generate(
request.prompt,
sampling_params,
request_id
)
# Collect all tokens
final_output = None
async for request_output in results_generator:
final_output = request_output
if final_output is None:
raise HTTPException(status_code=500,
detail="Generation failed")
return {
"id": request_id,
"text": final_output.outputs[0].text,
"finish_reason": final_output.outputs[0].finish_reason
}
# Run with: uvicorn main:app --host 0.0.0.0 --port 8000 --workers 1
This implementation uses vLLM's AsyncLLMEngine for concurrent request handling with continuous batching, Server-Sent Events (SSE) for efficient token streaming (avoids multiple HTTP requests), Pydantic models for request validation (auto-generates OpenAPI docs), LatencyMetrics tracking for TTFT/inter-token monitoring, graceful error handling with request cancellation on client disconnect, and prompt caching enabled (enable_prefix_caching=True) for 50-70% TTFT reduction on repeated system prompts.
Key vLLM Settings:
dtype="float16": 2x memory reduction + 1.5-2x speedup vs FP32gpu_memory_utilization=0.9: Use 90% GPU memory (prevents OOM)max_num_batched_tokens=8192: Continuous batching buffer sizemax_num_seqs=64: Process up to 64 concurrent requests in same batchenable_prefix_caching=True: Cache KV states for repeated prompt prefixes
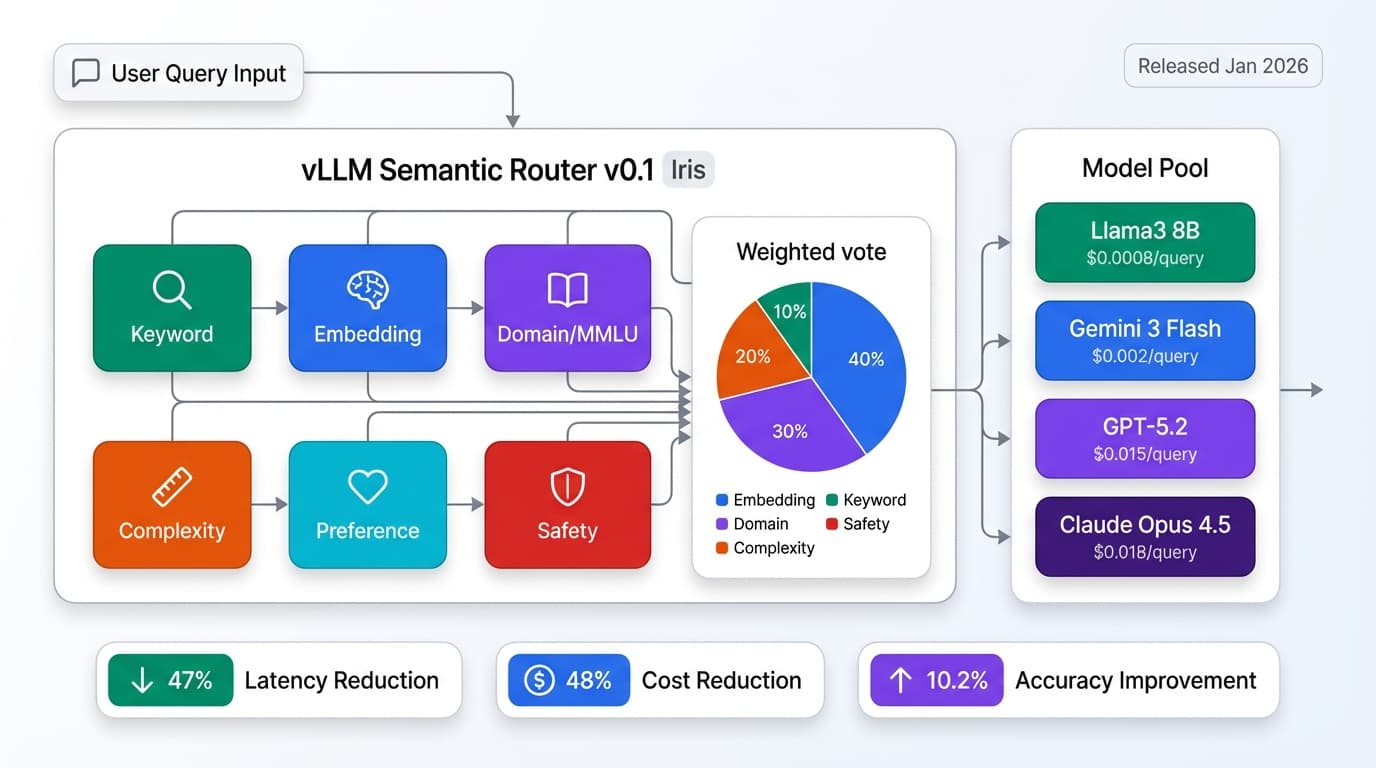
vLLM v0.1 "Iris" released January 2026 adds semantic routing for automatic model selection. For more on orchestration patterns, see our framework guide.
Optimization Strategies for Sub-100ms Latency
Four optimization strategies deliver the biggest latency improvements with minimal accuracy loss:
Strategy 1: Model Quantization reduces precision from FP32→FP16→INT8→INT4. FP16 (half precision) requires 2x less memory (14GB → 7GB for Llama-2-7B) and delivers 1.5-2x speedup with negligible accuracy loss (<0.5% on benchmarks). Enable with dtype="float16" in vLLM. INT8 (8-bit) reduces memory 4x and provides 2-3x speedup but degrades accuracy 1-2% on complex reasoning tasks. Use bitsandbytes library or vLLM's quantization="int8". INT4/GPTQ reduces memory 8x and speeds up 3-4x but degrades accuracy 2-5%. Best for large models (70B+) where memory is bottleneck. Use AutoGPTQ or llama.cpp GGUF format.
Strategy 2: Continuous Batching (vLLM's breakthrough) adds new requests dynamically to in-flight batches as sequences finish. Traditional static batching waits for batch to fill (adds latency) or processes requests individually (wastes GPU). vLLM's continuous batching achieves 2-10x throughput vs static batching by maximizing GPU utilization. Configure max_num_seqs=64 for concurrent sequence limit. The system automatically batches prefill and decode phases separately for optimal performance.
Strategy 3: PagedAttention (vLLM's secret weapon) applies virtual memory paging concepts to attention KV cache. Problem: KV cache for 2K token sequence requires 2GB GPU memory and fragments badly (60% GPU wasted on fragmentation). Solution: Store KV cache in non-contiguous "pages" like OS virtual memory. Impact: 2-4x memory efficiency enables serving 2-4x more requests on same GPU. This is transparent to users - enable automatically with vLLM. Result: serve larger batches → higher throughput → lower cost per token.
Strategy 4: Prompt Caching stores KV states for common prompt prefixes (system prompts, few-shot examples). If 90% of requests start with same 500-token system prompt, compute KV cache once and reuse. Impact: 50-70% TTFT reduction for cached prefixes. Example: uncached 700-token prompt = 800ms TTFT, cached 500-token prefix + 200-token unique = 300ms TTFT (62% reduction). Enable with enable_prefix_caching=True in vLLM.
| Optimization | Latency Impact | Throughput Impact | Cost Reduction | Complexity |
|---|---|---|---|---|
| FP16 Quantization | 1.5-2x faster inference | 1.5-2x more requests/GPU | 30-50% | Low (one config flag) |
| Continuous Batching | Same or better (less waiting) | 2-10x higher throughput | 50-80% | Low (automatic in vLLM) |
| PagedAttention | Minimal impact | 2-4x batch size increase | 50-75% | Low (automatic in vLLM) |
| Prompt Caching | 50-70% TTFT reduction | Higher effective throughput | 30-50% | Low (one config flag) |
Combined Impact: FP16 quantization + continuous batching + PagedAttention + prompt caching reduces serving costs by 40-60% while improving latency and throughput. All four optimizations are low-complexity (configuration flags in vLLM) with minimal accuracy trade-offs. For comprehensive cost strategies, see our optimization guide.
Infrastructure Patterns for GPU Serving
Four deployment patterns cover different scale requirements:
Pattern 1: Single GPU Instance serves <10 queries per second (QPS) for small-scale applications. Use single A100 (80GB) or A10G (24GB) instance running vLLM + FastAPI. Cost: $1.50-4/hr on AWS p4d.xlarge or GCP a2-highgpu-1g. Best for: MVPs, internal tools, development environments. Limitations: No redundancy (instance failure = downtime), limited scaling, single-region latency.
Pattern 2: Multi-GPU Tensor Parallelism splits large models (70B+ parameters) across 4-8 GPUs. Llama-2-70B requires 140GB VRAM (FP16), which doesn't fit single A100 (80GB). Solution: tensor parallelism splits model layers across GPUs. Configure tensor_parallel_size=4 for 4-GPU setup. Cost: $12-20/hr for 4×A100 instance. Best for: Large models requiring multiple GPUs per request. Limitations: Higher cost per request, doesn't improve throughput for smaller models.
Pattern 3: Load-Balanced Replicas horizontally scales with 3-10 independent vLLM instances behind load balancer. Each instance serves requests independently. Use NGINX, HAProxy, or AWS ALB for routing. Serve 50-500 QPS with 5×A100 instances. Cost: $7.50-20/hr for 5 instances. Best for: Production applications with high traffic, need redundancy. Benefits: Fault tolerance (instance failure doesn't break service), simple scaling (add replicas), distributed across regions.
Pattern 4: Autoscaling with Ray Serve dynamically scales from 0→50 GPUs based on traffic. Ray Serve orchestrates vLLM instances, automatically adding/removing replicas. Scale down to zero during off-peak (0 cost), scale up during traffic spikes. Cost: Pay only for active GPUs ($0-200/hr depending on traffic). Best for: Variable traffic patterns, cost optimization. Requires: Ray cluster setup, monitoring infrastructure, warm-up time tolerance (60-90s to scale from 0).
Recommended Starting Point:
<10QPS: Single A100 GPU ($2-4/hr)- 10-50 QPS: 3-5 load-balanced replicas ($7.50-20/hr)
- 50-500 QPS: Autoscaling with Ray Serve (variable cost)
For more on infrastructure patterns, see our gateway architecture guide.
Monitoring & SLAs for Production LLMs
Define SLAs (Service Level Agreements) based on user experience research and monitor continuously:
Time To First Token (TTFT) measures latency until first token appears. Target: P50 <100ms, P95 <200ms, P99 <500ms. Anything <200ms feels instant to users. TTFT >1s feels sluggish. Monitor using Prometheus histogram metrics: llm_ttft_seconds_bucket. Alert if P95 >200ms for 5 minutes.
Inter-Token Latency measures time between consecutive tokens. Target: P50 <15ms (66 tokens/sec), P95 <25ms (40 tokens/sec). Humans read ~250 words/min (4 words/sec), so 50+ tokens/sec feels instant. Below 20 tokens/sec feels choppy. Monitor using llm_inter_token_seconds_bucket. Alert if P95 >25ms.
End-to-End Latency for 100-token response should be P50 <2s, P95 <3s, P99 <5s. Calculated as TTFT + (100 tokens × inter-token latency). Users abandon after 3s, so keep P95 under this threshold.
Throughput Metrics: Track Requests Per Second (RPS) and Tokens Per Second (TPS) to measure capacity. Monitor GPU utilization: 70-90% is ideal (maximizes throughput), 100% means bottleneck (add capacity), <50% means over-provisioned (reduce cost).
| Metric | P50 Target | P95 Target | P99 Target | Alerting Threshold |
|---|---|---|---|---|
| TTFT (Time To First Token) | <100ms | <200ms | <500ms | P95 >200ms for 5min |
| Inter-Token Latency | <15ms | <25ms | <40ms | P95 >25ms for 5min |
| Total (100 tokens) | <2s | <3s | <5s | P95 >3s for 5min |
Monitoring Stack: Use Prometheus + Grafana for metrics visualization, OpenTelemetry for distributed tracing (track latency across microservices), and Datadog or New Relic for commercial alternatives with built-in LLM monitoring dashboards. vLLM exposes Prometheus metrics at /metrics endpoint automatically.
Critical Alerts: TTFT P95 >200ms (user experience degradation), inter-token P95 >25ms (choppy streaming), GPU utilization >95% for 10 minutes (capacity issue), error rate >1% (reliability issue). Configure PagerDuty for on-call rotation. For comprehensive monitoring patterns, see our MLOps guide.
Key Takeaways & Best Practices
After deploying streaming LLM APIs serving millions of requests, these patterns consistently deliver sub-100ms latency:
Streaming reduces perceived latency by 70% vs batch responses. Even if total latency is identical, users perceive streaming as faster because they see progress immediately. Always implement streaming for user-facing applications.
vLLM with PagedAttention achieves 2-24x throughput vs naive PyTorch implementations. PagedAttention (2-4x memory efficiency) + continuous batching (2-10x throughput) + FP16 quantization (1.5-2x speedup) compound multiplicatively. Switching from PyTorch to vLLM is the highest-leverage optimization.
Target SLAs: TTFT <100ms (P50), <200ms (P95), <500ms (P99). These thresholds align with human perception research. Sub-200ms feels instant, 200-1000ms feels responsive, >1000ms feels slow. Measure and optimize P95/P99, not just averages (outliers hurt user experience most).
Key optimizations combined reduce costs 40%: FP16 quantization (30-50% savings) + continuous batching (50-80% savings) + PagedAttention (50-75% savings) + prompt caching (30-50% savings). All are low-complexity configuration changes in vLLM, not code rewrites.
Infrastructure: Start single GPU, scale to load-balanced replicas. Begin with single A100 instance for <10 QPS ($2-4/hr). Scale to 3-5 replicas for 10-50 QPS ($7.50-20/hr). Only adopt autoscaling (Ray Serve) if traffic patterns are highly variable and cost optimization justifies complexity.
Monitor P50/P95/P99 latency with Prometheus + Grafana. Averages hide critical outliers. A P50 of 100ms with P99 of 5s means 1% of users experience terrible UX. Always monitor percentiles and alert on P95 degradation.
Cost vs Latency Trade-offs:
- Ultra-low latency (
<50msTTFT): Requires aggressive optimizations (INT8 quantization, multi-GPU, edge deployment) → 3x cost. Best for: real-time voice, gaming, high-frequency trading. - Balanced (
<200msTTFT): Standard optimizations (FP16, vLLM, prompt caching) → baseline cost. Best for: chatbots, customer support, content generation. - Cost-optimized (
<2sTTFT): Maximum batching, lower-priority queue → 60% cost savings. Best for: batch processing, background tasks, non-interactive use cases.
Implement streaming today. Your users will perceive your LLM as 70% faster even with identical total latency. The psychological impact of seeing immediate progress dramatically improves user satisfaction and reduces abandonment rates. Start with the FastAPI + vLLM code above and iterate toward sub-100ms TTFT.