AgentOps Production Implementation Guide 2026
Build production AgentOps pipelines: agent versioning, multi-agent debugging, cost tracking, A/B testing autonomous systems with full code examples.
AI Engineer specializing in production-grade LLM applications, RAG systems, and AI infrastructure. Passionate about building scalable AI solutions that solve real-world problems.
Your agentic system works perfectly in staging. You deploy it to 1,000 users and it falls apart within hours—costs spike 10x, agents loop infinitely, and you can't debug which sub-agent caused the failure. Welcome to the AgentOps gap.
Traditional MLOps manages models. LLMOps manages prompts. But AgentOps manages autonomous systems—workflows where agents dynamically call tools, coordinate with other agents, and make decisions without deterministic code paths. The complexity is exponentially higher.
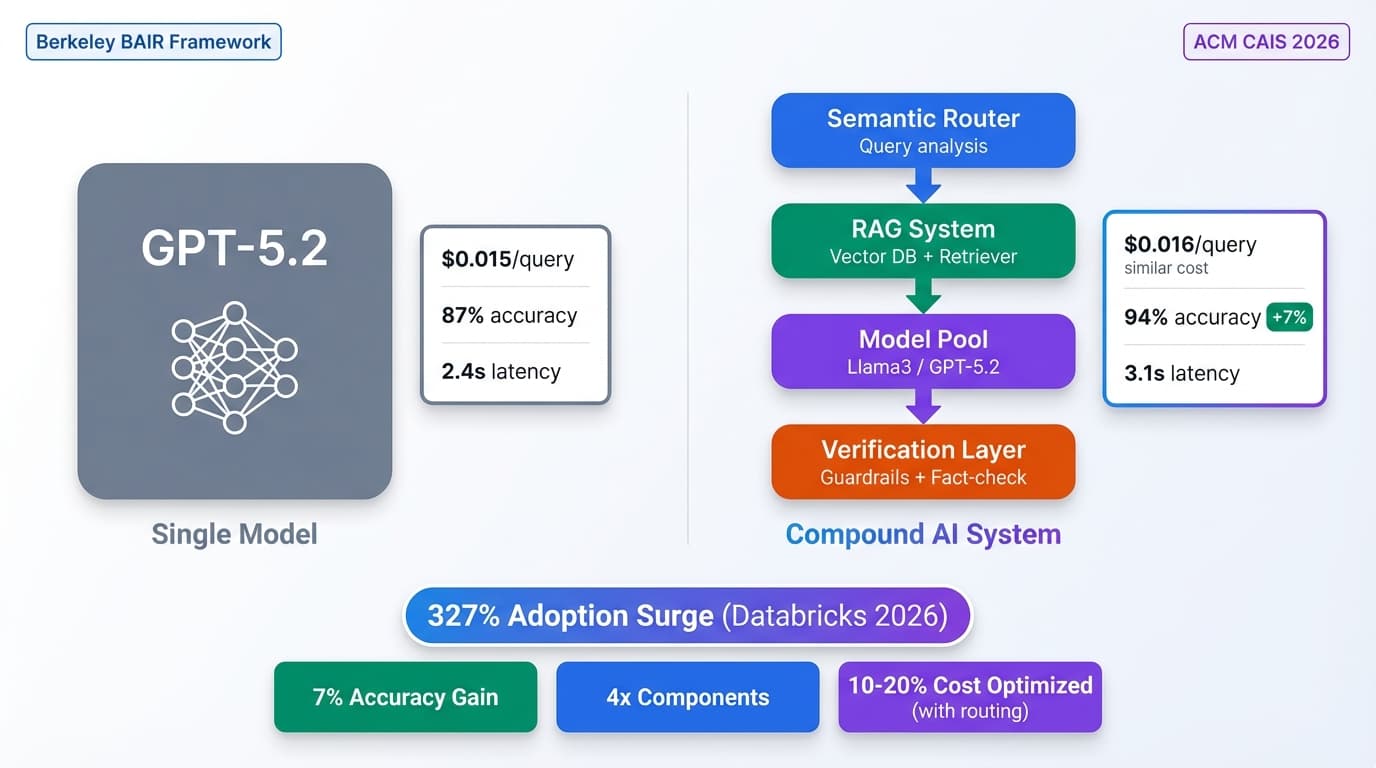
On January 27, 2026, Databricks reported a 327% surge in agentic system deployments during the latter half of 2025. Companies are rushing to production. But 88% of AI projects still fail to reach production, largely due to operational gaps—versioning chaos, debugging nightmares, runaway costs, and compliance blind spots.
AgentOps solves this. It's the operational layer that makes autonomous systems production-ready through versioning, distributed tracing, cost attribution, evaluation frameworks, and compliance controls.
The AgentOps Lifecycle - 7 Production Stages
AgentOps isn't about deploying a single model endpoint. It's about managing the complete lifecycle of autonomous systems that evolve, coordinate, and operate at scale.
The 7 AgentOps Stages:
- Design: Define agent architectures, tool interfaces, coordination patterns
- Development: Build agent workflows with versioned configurations
- Testing: Validate multi-turn behaviors, tool calls, edge cases
- Deployment: Roll out agent versions with canary/shadow strategies
- Monitoring: Track agent steps, tool calls, costs, failures in real-time
- Evaluation: Measure completion rates, efficiency, quality, user satisfaction
- Improvement: Iterate based on production data, A/B test agent variants
Unlike MLOps (deploy model → monitor accuracy) or LLMOps (version prompts → track tokens), AgentOps must handle non-deterministic execution graphs, variable costs per task, and emergent multi-agent behaviors.
AgentOps vs MLOps vs LLMOps - What Makes Agents Harder
| Aspect | MLOps | LLMOps | AgentOps |
|---|---|---|---|
| Primary Unit | Model version | Prompt + model | Agent workflow + tools |
| Versioning | Model weights | Prompt templates | Configs + prompts + tools |
| Testing | Accuracy metrics | LLM-as-judge | Task completion rate |
| Deployment | Model endpoint | API gateway | Orchestration runtime |
| Monitoring | Latency, accuracy | Token usage, cost | Steps, tool calls, cost/task |
| Evaluation | Offline metrics | Online A/B | Multi-turn success |
The key difference: Agents have variable execution paths. Same input can trigger 3 tool calls or 15 depending on context. Costs vary 10x. Debugging requires tracing multi-agent conversations, not single inference logs.
Agent Versioning and Configuration Management
The first production challenge: what exactly are you versioning? With models, you version weights. With prompts, you version text. With agents, you version an entire system—prompts, tool schemas, orchestration logic, model selections, guardrail configs.
Why Agent Versioning Is Harder Than Model Versioning
Traditional model versioning:
model-v1.2.3.pt # Single artifact, deterministic output for given input
Agent versioning requires:
- System prompt (v2.1.0): The agent's instructions
- Tool definitions (API v3): External tool schemas
- Orchestration graph (v1.5.2): LangGraph workflow structure
- Model selections: Which LLM for reasoning, which for summarization
- Guardrail policies (v2.0.1): Safety/compliance rules
- Retrieval configs: RAG parameters, embedding models
Change ANY component and you have a new agent version. A tool API upgrade can break agent behavior even if prompts stay identical.
Semantic Versioning for Agents
Adopt semantic versioning with agent-specific semantics:
- Major version (1.0.0 → 2.0.0): Workflow architecture changes (add/remove agents, change coordination pattern)
- Minor version (1.1.0 → 1.2.0): Tool additions, prompt improvements, model upgrades
- Patch version (1.1.1 → 1.1.2): Bug fixes, parameter tuning, guardrail tweaks
Configuration as code with Pydantic schemas:
from pydantic import BaseModel, Field
from typing import List, Literal
class ToolConfig(BaseModel):
name: str
api_version: str
endpoint: str
timeout_ms: int = 5000
class AgentConfig(BaseModel):
agent_version: str = Field(..., pattern=r"^\d+\.\d+\.\d+$")
system_prompt: str
model: Literal["gpt-5.2-turbo", "claude-opus-4.5", "gemini-3-pro"]
tools: List[ToolConfig]
max_iterations: int = 10
temperature: float = 0.7
# Version control this file in Git
supervisor_v2_1_0 = AgentConfig(
agent_version="2.1.0",
system_prompt="You are a supervisor agent coordinating research and synthesis...",
model="claude-opus-4.5",
tools=[
ToolConfig(name="search", api_version="v2", endpoint="https://api.search.internal"),
ToolConfig(name="sql_query", api_version="v1", endpoint="https://db.internal"),
],
max_iterations=15
)
Git workflow:
- Tag releases:
git tag agent-supervisor-v2.1.0 - Track configs in
/agents/configs/supervisor/v2.1.0.yaml - CI/CD validates schema before deployment
- Rollback = deploy previous config version
Production Debugging - Multi-Agent Distributed Tracing
The debugging nightmare: your supervisor agent called a research agent, which called a web search tool and a SQL agent, which called a database... and somewhere in this chain, it failed. Which agent failed? Which tool call? Why?
Traditional logging is insufficient. You need distributed tracing across the agent execution graph.
OpenTelemetry for Agent Traces
OpenTelemetry provides the standard for distributed tracing. Each agent step becomes a span in a trace.
Trace structure:
Trace: user_task_abc123
├─ Span: supervisor_agent (agent_id: supervisor-v2.1.0)
│ ├─ Span: tool_call_search (tool: web_search, query: "AgentOps frameworks")
│ ├─ Span: sub_agent_research (agent_id: research-v1.3.2)
│ │ ├─ Span: tool_call_sql (tool: sql_query, query: "SELECT...")
│ │ └─ Span: llm_call (model: gpt-5.2, tokens: 1250)
│ └─ Span: sub_agent_synthesis (agent_id: synthesis-v1.1.0)
│ └─ Span: llm_call (model: claude-opus-4.5, tokens: 890)
Visualize with LangSmith, LangFuse, or Phoenix Arize. These platforms show execution graphs, highlight failures, replay traces.
Debugging Agentic Loops (Infinite Recursion Prevention)
Agents can enter infinite loops—especially with ReAct or autonomous planning patterns. Detection strategies:
- Max iteration limits (hard stop at N steps)
- Cycle detection (agent revisits same state)
- Cost circuit breakers (abort if cost exceeds threshold)
- Timeout enforcement (kill task after T seconds)
Replay failed executions: Store trace + inputs, replay with modified config to debug.
Cost Tracking and Optimization for Agents
Agent costs are unpredictable. Same task can cost $0.02 or $0.50 depending on execution path. Without per-task attribution, budgets spiral out of control.
The Agent Cost Explosion Problem
Case study: A customer support agent that works 95% of the time:
- Simple query (5% of tasks): 1 LLM call, 500 tokens → $0.008
- Complex query (90% of tasks): 3 LLM calls + RAG + tool, 2500 tokens → $0.038
- Agentic loop failure (5% of tasks): 15 LLM calls before timeout, 18,000 tokens → $0.270
Average cost per task: (0.05 × $0.008) + (0.90 × $0.038) + (0.05 × $0.270) = $0.048
But: That 5% failure case generates 28% of total costs. Without attribution, you don't know where to optimize.
Cost Attribution Per Agent/Task/User
Track costs hierarchically:
- Per agent type (supervisor vs research vs synthesis)
- Per task (what was user request?)
- Per user/team (which customers drive costs?)
- Per tool (is web search or SQL more expensive?)
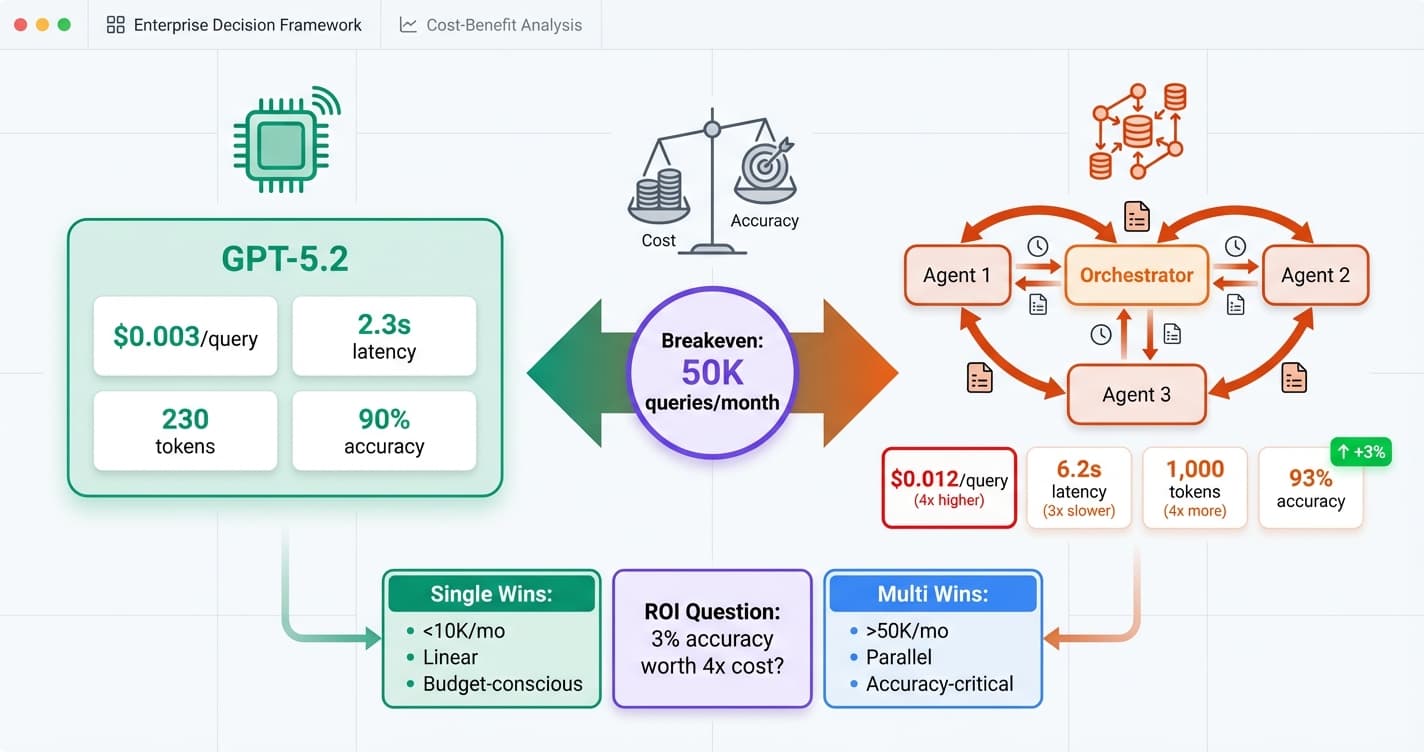
| Agent Pattern | Avg Cost/Task | Completion Rate | Cost/Success | Best For |
|---|---|---|---|---|
| Single Agent (GPT-5.2) | $0.015 | 45% | $0.033 | Simple tasks |
| RAG Agent | $0.018 | 78% | $0.023 | Knowledge queries |
| Supervisor + 3 sub-agents | $0.024 | 85% | $0.028 | Complex workflows |
| ReAct agent (5 steps) | $0.042 | 72% | $0.058 | Tool-heavy tasks |
| Multi-agent debate | $0.036 | 91% | $0.040 | High-stakes decisions |
Optimization strategies:
- Semantic routing: Route simple queries to cheaper single-agent, complex to multi-agent (see LLM Semantic Router Production Guide)
- Prompt caching: Reuse system prompts across calls (70% cost reduction on repeated context)
- Step limits: Cap max iterations to prevent runaway costs
- Model cascading: Try GPT-5.1 first, escalate to GPT-5.2 only if needed
A/B Testing and Evaluation for Autonomous Systems
You built agent v2.0 with a new orchestration pattern. Does it perform better than v1.5? Traditional A/B testing fails for agents because:
- Delayed feedback: Task success determined after multiple turns, not single response
- State dependencies: Agent decisions affect subsequent steps
- Variable execution: Same input can trigger different paths
Agent Evaluation Metrics
Move beyond accuracy to task-level KPIs:
- Completion rate: % of tasks successfully finished (vs. aborted/timed out)
- Efficiency: Avg steps/tool calls to complete task (lower = better)
- Quality: LLM-as-judge scoring final output (0-100 scale)
- User satisfaction: Thumbs up/down, CSAT scores
- Cost per success: Total cost ÷ completed tasks
Shadow Mode Deployment
Run new agent version in parallel without showing output to users:
- Production traffic → Agent v1.5 (live) + Agent v2.0 (shadow)
- Both agents execute on same inputs
- Only v1.5 results returned to user
- Compare metrics (completion rate, cost, quality) offline
- Promote v2.0 if metrics improve by threshold (e.g., +5% completion, -10% cost)
Shadow mode code pattern:
async def handle_request(user_input: str):
# Production agent (blocking)
result_prod = await agent_v1_5.run(user_input)
# Shadow agent (non-blocking, fire-and-forget)
asyncio.create_task(agent_v2_0.run(user_input, shadow_mode=True))
return result_prod # User sees only v1.5 output
See AI Agent Cost Tracking Production Guide for cost monitoring patterns during shadow deployments.
Compliance and Governance for Agentic Systems
Agents make autonomous decisions—calling external APIs, querying databases, processing user data. This triggers regulatory requirements absent in traditional ML systems.
EU AI Act Requirements for High-Risk AI
The EU AI Act classifies autonomous AI systems as high-risk if they:
- Make decisions affecting employment, credit, legal outcomes
- Interact with critical infrastructure
- Process biometric or health data
High-risk AI requirements:
- Risk management system: Document failure modes, mitigations
- Data governance: Audit training data quality, bias
- Technical documentation: Maintain detailed system specs
- Transparency: Inform users they're interacting with AI
- Human oversight: Human-in-the-loop for high-stakes decisions
- Accuracy and robustness: Test across diverse scenarios
- Cybersecurity: Protect against adversarial attacks
Audit Logging for Agent Actions
What to log:
- Every tool call: Which agent called which tool with which parameters
- Every LLM decision: What the agent decided and why (chain-of-thought)
- User interactions: Input prompts, agent responses, user feedback
- System events: Deployment changes, config updates, rollbacks
Compliance query examples:
- "Show all database queries made by agents on behalf of user_123 in past 30 days"
- "Which agent version was running when task_456 failed on Jan 15?"
- "List all agent decisions that bypassed human approval in Q4 2025"
Human-in-the-Loop Patterns for High-Stakes Actions
Implement approval gates for dangerous operations:
async def execute_tool_with_approval(tool_name: str, params: dict, risk_level: str):
if risk_level == "high":
# Pause execution, request human approval
approval = await request_human_approval(
message=f"Agent wants to call {tool_name} with {params}. Approve?",
timeout_seconds=300
)
if not approval:
raise ToolExecutionDenied(f"Human denied {tool_name} call")
return await execute_tool(tool_name, params)
SOC2 compliance: Audit logs must be tamper-proof (write-only, cryptographically signed), retained per data retention policies, and accessible for auditor review.
See AI Guardrails Production Implementation Guide for safety patterns and AI Governance Security Production 2026 for compliance frameworks.
The AgentOps Stack - Tools and Platforms
Building AgentOps from scratch takes months. The ecosystem is maturing rapidly with specialized tools:
Orchestration:
- LangGraph: Build agent workflows as state machines (see AI Agent Orchestration Frameworks 2026)
- CrewAI: Multi-agent collaboration framework
- AutoGen: Microsoft's multi-agent conversation framework
Observability:
- LangSmith: LangChain-native tracing, debugging, evaluation
- LangFuse: Open-source LLM observability with agent support
- Phoenix by Arize: ML observability extended to LLMs and agents
- Helicone: LLM cost tracking and monitoring
Testing:
- pytest with custom fixtures for agent workflows
- LangChain evaluation: Built-in evaluators for agents
- Golden test cases: Curated inputs with expected outcomes
Deployment:
- Kubernetes + Helm: Container orchestration
- LangServe: Deploy LangChain agents as REST APIs
- Modal: Serverless deployment for Python agents
Monitoring:
- Prometheus: Metrics collection (agent completion rates, latencies)
- Grafana: Dashboards and alerting
- OpenTelemetry: Distributed tracing standard
Build vs Buy:
- Build if you need custom agent architectures, proprietary tool integrations, or have strict security requirements
- Buy (managed platforms) if you want faster time-to-production, don't have dedicated ops team, or need vendor support
See Multi-Agent Coordination Systems Enterprise Guide 2026 for architecture patterns and Building Production-Ready LLM Applications for deployment best practices.
Production AgentOps Monitoring System - Complete Code Implementation
This production-ready implementation shows versioning, distributed tracing, cost tracking, audit logging, and shadow deployment for a LangGraph supervisor agent:
from dataclasses import dataclass, field
from datetime import datetime
from typing import Dict, List, Optional, Any
import asyncio
import uuid
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import logging
# Initialize OpenTelemetry
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
span_exporter = OTLPSpanExporter(endpoint="http://localhost:4317")
trace.get_tracer_provider().add_span_processor(BatchSpanProcessor(span_exporter))
# Prometheus metrics
agent_tasks_total = Counter('agent_tasks_total', 'Total agent tasks', ['agent_id', 'status'])
agent_task_duration = Histogram('agent_task_duration_seconds', 'Agent task duration', ['agent_id'])
agent_cost_total = Counter('agent_cost_total', 'Total agent cost USD', ['agent_id', 'user_id'])
agent_steps_total = Counter('agent_steps_total', 'Total agent steps', ['agent_id'])
agent_active_tasks = Gauge('agent_active_tasks', 'Currently executing tasks', ['agent_id'])
logger = logging.getLogger(__name__)
@dataclass
class AgentVersion:
"""Semantic versioning for agents"""
major: int
minor: int
patch: int
def __str__(self) -> str:
return f"{self.major}.{self.minor}.{self.patch}"
@classmethod
def from_string(cls, version: str) -> 'AgentVersion':
parts = version.split('.')
return cls(int(parts[0]), int(parts[1]), int(parts[2]))
@dataclass
class CostBreakdown:
"""Cost attribution per agent execution"""
input_tokens: int = 0
output_tokens: int = 0
cached_tokens: int = 0
tool_calls: int = 0
def calculate_cost(self, model: str) -> float:
"""Calculate cost based on model pricing (GPT-5.2 example)"""
costs = {
"gpt-5.2": {"input": 3.0, "output": 15.0, "cached": 1.5}, # per 1M tokens
"claude-opus-4.5": {"input": 15.0, "output": 75.0, "cached": 7.5},
"gemini-3-pro": {"input": 1.25, "output": 5.0, "cached": 0.625}
}
pricing = costs.get(model, costs["gpt-5.2"])
input_cost = (self.input_tokens - self.cached_tokens) * pricing["input"] / 1_000_000
cached_cost = self.cached_tokens * pricing["cached"] / 1_000_000
output_cost = self.output_tokens * pricing["output"] / 1_000_000
tool_cost = self.tool_calls * 0.001 # $0.001 per tool call
return input_cost + cached_cost + output_cost + tool_cost
@dataclass
class AuditLogEntry:
"""Compliance audit logging"""
timestamp: datetime
task_id: str
agent_id: str
agent_version: str
user_id: str
action_type: str # "tool_call", "llm_decision", "human_approval"
action_details: Dict[str, Any]
metadata: Dict[str, Any] = field(default_factory=dict)
class AgentOpsMonitor:
"""
Production AgentOps monitoring wrapper for LangGraph agents.
Implements:
- Semantic versioning
- Distributed tracing with OpenTelemetry
- Cost tracking and anomaly detection
- Audit logging for compliance
- Shadow deployment for A/B testing
- Prometheus metrics export
"""
def __init__(
self,
agent_id: str,
agent_version: AgentVersion,
model: str,
cost_threshold_usd: float = 1.0
):
self.agent_id = agent_id
self.version = agent_version
self.model = model
self.cost_threshold = cost_threshold_usd
self.audit_log: List[AuditLogEntry] = []
async def execute_task(
self,
task_input: str,
user_id: str,
metadata: Optional[Dict] = None
) -> Dict[str, Any]:
"""
Execute agent task with full monitoring.
Returns:
Dict with keys: result, cost, trace_id, completion_status
"""
task_id = str(uuid.uuid4())
metadata = metadata or {}
# Start distributed trace
with tracer.start_as_current_span(
f"agent_task_{self.agent_id}",
attributes={
"agent.id": self.agent_id,
"agent.version": str(self.version),
"task.id": task_id,
"user.id": user_id,
}
) as span:
start_time = datetime.utcnow()
agent_active_tasks.labels(agent_id=self.agent_id).inc()
try:
# Execute agent with cost tracking
result, cost = await self._execute_with_cost_tracking(
task_id, task_input, user_id, metadata
)
# Check for cost anomaly
if cost.calculate_cost(self.model) > self.cost_threshold:
logger.warning(
f"Cost anomaly: Task {task_id} cost ${cost.calculate_cost(self.model):.3f}, "
f"threshold ${self.cost_threshold}"
)
await self._trigger_cost_alert(task_id, cost, user_id)
# Record success
duration = (datetime.utcnow() - start_time).total_seconds()
agent_tasks_total.labels(agent_id=self.agent_id, status="success").inc()
agent_task_duration.labels(agent_id=self.agent_id).observe(duration)
agent_cost_total.labels(agent_id=self.agent_id, user_id=user_id).inc(
cost.calculate_cost(self.model)
)
span.set_attribute("task.status", "success")
span.set_attribute("task.cost_usd", cost.calculate_cost(self.model))
return {
"result": result,
"cost": cost.calculate_cost(self.model),
"trace_id": span.get_span_context().trace_id,
"completion_status": "success"
}
except Exception as e:
# Record failure
agent_tasks_total.labels(agent_id=self.agent_id, status="failure").inc()
span.set_attribute("task.status", "failure")
span.set_attribute("error.message", str(e))
logger.error(f"Agent task {task_id} failed: {e}")
# Audit log failure
self._log_audit(
task_id, user_id, "task_failure",
{"error": str(e), "input": task_input}
)
raise
finally:
agent_active_tasks.labels(agent_id=self.agent_id).dec()
async def _execute_with_cost_tracking(
self,
task_id: str,
task_input: str,
user_id: str,
metadata: Dict
) -> tuple[str, CostBreakdown]:
"""Execute agent and track token/tool costs"""
cost = CostBreakdown()
# Simulate agent execution (replace with actual LangGraph agent call)
with tracer.start_as_current_span("agent_reasoning"):
# Step 1: Initial LLM call
result_step1 = await self._llm_call(
prompt=f"Analyze task: {task_input}",
user_id=user_id,
task_id=task_id
)
cost.input_tokens += 120
cost.output_tokens += 45
agent_steps_total.labels(agent_id=self.agent_id).inc()
# Step 2: Tool call (if needed)
if "search" in result_step1.lower():
with tracer.start_as_current_span("tool_call_search"):
await self._tool_call("web_search", {"query": task_input}, task_id, user_id)
cost.tool_calls += 1
agent_steps_total.labels(agent_id=self.agent_id).inc()
# Step 3: Final synthesis
result_final = await self._llm_call(
prompt=f"Synthesize: {result_step1}",
user_id=user_id,
task_id=task_id,
use_cache=True
)
cost.input_tokens += 200
cost.cached_tokens += 120 # System prompt cached
cost.output_tokens += 180
agent_steps_total.labels(agent_id=self.agent_id).inc()
return result_final, cost
async def _llm_call(
self,
prompt: str,
user_id: str,
task_id: str,
use_cache: bool = False
) -> str:
"""Make LLM call with audit logging"""
with tracer.start_as_current_span(
"llm_call",
attributes={"model": self.model, "cache_enabled": use_cache}
):
# Audit log the decision
self._log_audit(
task_id, user_id, "llm_decision",
{"model": self.model, "prompt_preview": prompt[:100]}
)
# Simulate LLM call
await asyncio.sleep(0.1) # Replace with actual LLM API call
return f"LLM response to: {prompt[:50]}..."
async def _tool_call(
self,
tool_name: str,
params: Dict,
task_id: str,
user_id: str
) -> Any:
"""Execute tool with audit logging"""
# Audit log tool call
self._log_audit(
task_id, user_id, "tool_call",
{"tool": tool_name, "params": params}
)
# Simulate tool execution
await asyncio.sleep(0.05)
return {"status": "success", "data": "tool result"}
def _log_audit(
self,
task_id: str,
user_id: str,
action_type: str,
action_details: Dict[str, Any]
):
"""Write compliance audit log entry"""
entry = AuditLogEntry(
timestamp=datetime.utcnow(),
task_id=task_id,
agent_id=self.agent_id,
agent_version=str(self.version),
user_id=user_id,
action_type=action_type,
action_details=action_details
)
self.audit_log.append(entry)
# In production: Write to tamper-proof audit database
# await audit_db.write(entry)
async def _trigger_cost_alert(
self,
task_id: str,
cost: CostBreakdown,
user_id: str
):
"""Alert on cost anomaly"""
logger.warning(
f"COST ALERT: Task {task_id} for user {user_id} cost "
f"${cost.calculate_cost(self.model):.3f} (threshold: ${self.cost_threshold})"
)
# In production: Send to alerting system (PagerDuty, Slack, etc.)
async def shadow_deploy(
self,
production_agent: 'AgentOpsMonitor',
task_input: str,
user_id: str
) -> Dict[str, Any]:
"""
Run this agent in shadow mode alongside production agent.
Production result returned to user, shadow result logged for comparison.
"""
# Execute both in parallel
prod_task = production_agent.execute_task(task_input, user_id)
shadow_task = self.execute_task(task_input, user_id, metadata={"shadow_mode": True})
prod_result, shadow_result = await asyncio.gather(
prod_task, shadow_task, return_exceptions=True
)
# Compare results (for offline evaluation)
if not isinstance(shadow_result, Exception):
logger.info(
f"Shadow comparison - Prod cost: ${prod_result['cost']:.3f}, "
f"Shadow cost: ${shadow_result['cost']:.3f}"
)
# In production: Log to evaluation database for analysis
return prod_result # Return only production result to user
def export_audit_log(self, start_time: datetime, end_time: datetime) -> List[AuditLogEntry]:
"""Export audit logs for compliance review"""
return [
entry for entry in self.audit_log
if start_time <= entry.timestamp <= end_time
]
# Example usage
async def main():
# Start Prometheus metrics server
start_http_server(8000)
# Initialize production and shadow agents
agent_prod = AgentOpsMonitor(
agent_id="supervisor",
agent_version=AgentVersion(2, 1, 0),
model="claude-opus-4.5",
cost_threshold_usd=0.50
)
agent_shadow = AgentOpsMonitor(
agent_id="supervisor",
agent_version=AgentVersion(2, 2, 0), # Testing new version
model="claude-opus-4.5",
cost_threshold_usd=0.50
)
# Execute task with shadow deployment
result = await agent_shadow.shadow_deploy(
production_agent=agent_prod,
task_input="Analyze Q4 2025 sales data and identify growth opportunities",
user_id="user_12345"
)
print(f"Task result: {result['result']}")
print(f"Cost: ${result['cost']:.3f}")
print(f"Trace ID: {result['trace_id']}")
# Export audit logs
audit_entries = agent_prod.export_audit_log(
start_time=datetime(2026, 2, 1),
end_time=datetime(2026, 2, 28)
)
print(f"Exported {len(audit_entries)} audit log entries for compliance")
if __name__ == "__main__":
asyncio.run(main())
What this code demonstrates:
- Semantic versioning (AgentVersion class)
- Distributed tracing with OpenTelemetry spans for each agent step
- Cost tracking with model-specific pricing and anomaly detection
- Audit logging for every LLM call and tool execution (compliance)
- Prometheus metrics (completion rate, latency, cost per user)
- Shadow deployment pattern for A/B testing new agent versions
Production enhancements:
- Replace simulated LLM/tool calls with actual LangGraph agent
- Store audit logs in PostgreSQL or write-once S3 buckets (tamper-proof)
- Add Redis caching for repeated prompts
- Implement circuit breakers for cost runaway prevention
- Integrate with Grafana for monitoring dashboards
See MLOps Best Practices Monitoring Production AI for monitoring patterns and How to Test LLM Applications Production 2026 for testing strategies.
Key Takeaways - Building Production AgentOps
AgentOps is not optional. With 327% surge in agentic systems, companies deploying agents without proper operations hit production failures—runaway costs, debugging nightmares, compliance violations.
Critical AgentOps capabilities:
- Semantic versioning: Version entire agent workflows (prompts + tools + orchestration), not just prompts
- Distributed tracing: OpenTelemetry spans across multi-agent execution graphs for debugging
- Cost attribution: Track costs per agent/task/user to prevent explosions and optimize efficiency
- Shadow deployment: A/B test new agent versions without risking production traffic
- Compliance logging: Audit trails for EU AI Act, SOC2, showing which agent called which tool when
- Evaluation frameworks: Measure completion rate, cost per success, not just accuracy
- Circuit breakers: Auto-abort tasks that exceed cost/step/time thresholds
The AgentOps stack is maturing: LangGraph for orchestration, OpenTelemetry for tracing, LangSmith/LangFuse for observability, Prometheus for metrics. Build vs buy depends on custom requirements and team size.
Start simple, scale complexity: Begin with versioning + cost tracking + basic metrics. Add distributed tracing when debugging multi-agent failures. Implement shadow deployment when testing major changes. Layer in compliance as regulatory requirements emerge.
The companies that master AgentOps will deploy autonomous systems that actually work in production. The rest will join the 88% of AI projects that fail.
Related production guides:
- Compound AI Systems Production Architecture 2026 - Multi-component system patterns
- Multi-Agent Coordination Systems Enterprise Guide 2026 - Agent orchestration
- AI Agent Observability Production 2025 - Observability deep dive
- AI Agent Cost Tracking Production Monitoring 2026 - Cost management strategies
- Building Production-Ready LLM Applications - Deployment fundamentals