Data Privacy Compliance Guide for Intelligent Systems 2026
AI Engineer specializing in production-grade LLM applications, RAG systems, and AI infrastructure. Passionate about building scalable AI solutions that solve real-world problems.
On August 2, 2026, the European Union's AI Act compliance deadline arrives. Organizations deploying high-risk AI systems face fines up to 7% of global annual turnover for non-compliance. Meanwhile, GDPR enforcement has already generated $5.88 billion in cumulative fines since 2018, with AI-related violations representing the fastest-growing category.
This isn't a legal overview. This is an operational guide for engineering and compliance teams implementing privacy-preserving AI systems that meet GDPR, CCPA, and EU AI Act requirements. We'll cover tactical implementation: training data provenance, consent management systems, privacy impact assessments, and production code examples proven in regulated industries.
The Compliance Convergence Crisis
Enterprise AI teams face an unprecedented regulatory landscape in 2026:
Regulatory Timeline
EU AI Act (Compliance deadline: August 2, 2026)
- High-risk AI system classification requirements
- Mandatory conformity assessments before deployment
- Ongoing monitoring and reporting obligations
- Penalties: Up to €35 million or 7% of global turnover
GDPR (Enforcement intensifying in 2026)
- 20% increase in enforcement actions year-over-year
- Average fine: €2.4 million per violation
- New guidance on AI-specific requirements
- Expanding to cover AI training data explicitly
U.S. State Privacy Laws (20 new laws in 2026)
- California CPRA amendments for automated decision-making
- Virginia CDPA AI-specific provisions
- Colorado CPA requirements for algorithmic transparency
- Patchwork compliance challenge for multi-state operations
Sector-Specific Regulations
- HIPAA for healthcare AI (diagnosis, treatment planning)
- GLBA for financial services (credit scoring, fraud detection)
- FERPA for educational AI (student assessment, admissions)
- FTC enforcement for unfair/deceptive AI practices
Financial Risk Assessment
Direct penalty exposure:
- GDPR: €20 million or 4% of global turnover (data violations)
- GDPR: €10 million or 2% of global turnover (procedural violations)
- EU AI Act: €35 million or 7% of global turnover (high-risk violations)
- CCPA: $7,500 per intentional violation, $2,500 per unintentional
Indirect costs:
- Incident response and remediation: $4.45 million average (IBM 2025 Cost of Data Breach Report)
- Reputation damage: 65% of consumers avoid companies after privacy violations
- Operational disruption: Systems may require shutdown pending compliance
Real example: In Q4 2025, a multinational retailer received a €65 million GDPR fine for using customer purchase data to train recommendation AI without proper legal basis. The violation: legitimate interests assessment was insufficiently documented.
High-Risk AI System Classification
The EU AI Act introduces mandatory requirements for "high-risk" AI systems. Understanding classification determines your compliance obligations.
High-Risk Categories
Employment and HR:
- Recruitment and hiring systems
- Performance evaluation and promotion
- Task allocation and monitoring
- Termination decision support
Education and Training:
- Student assessment and grading
- Admission decisions
- Educational institution selection
- Proctoring and cheating detection
Essential Services Access:
- Credit scoring and loan approval
- Insurance pricing and claims
- Social benefit eligibility
- Emergency response dispatch
Law Enforcement:
- Predictive policing and crime prevention
- Evidence assessment and risk scoring
- Individual risk assessment for offenses
- Lie detection and emotion recognition
Critical Infrastructure:
- Traffic management systems
- Utility resource allocation
- Industrial safety systems
- Healthcare diagnostic support
Classification Decision Tree
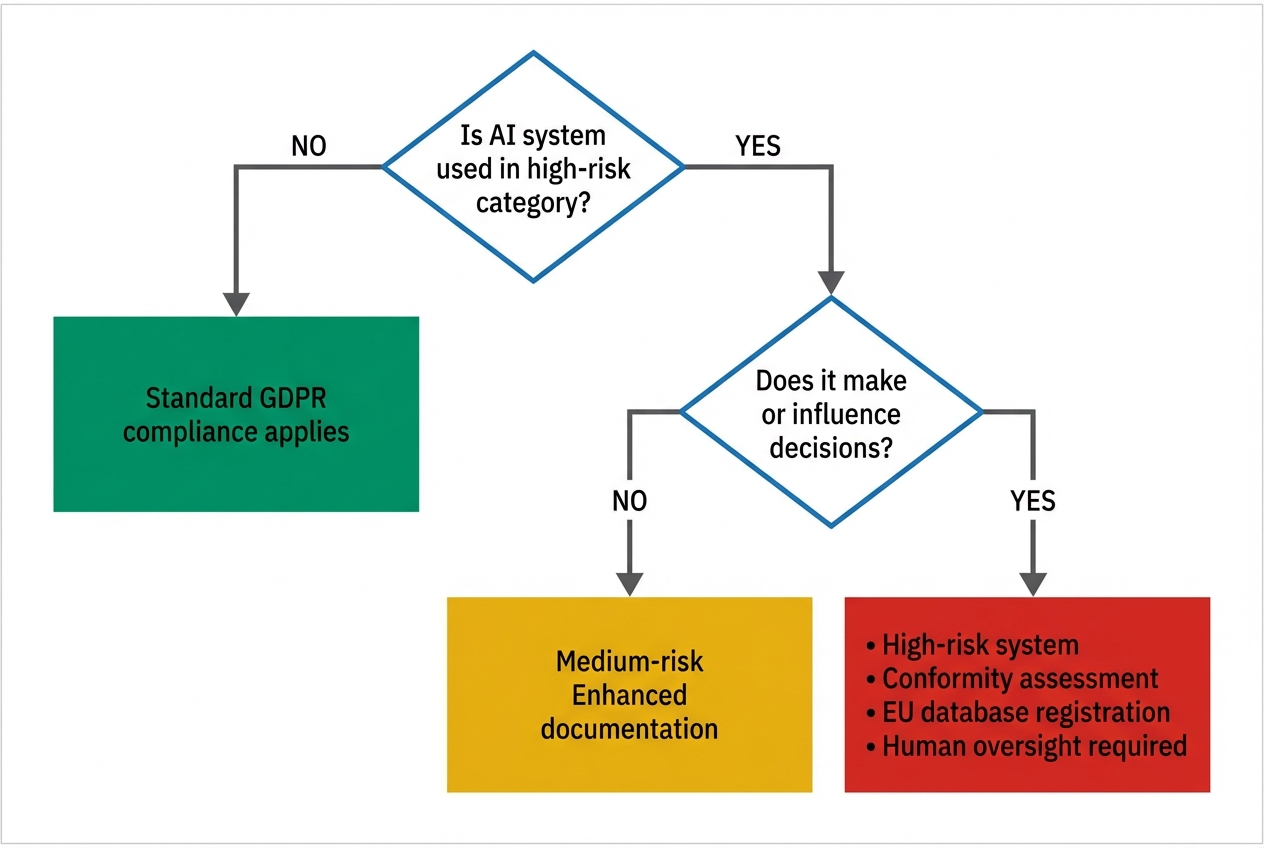
Critical note: Even if not high-risk under EU AI Act, GDPR Article 22 prohibits automated decision-making with legal/significant effects without explicit consent or contractual necessity.
Privacy Impact Assessments for AI
Data Protection Impact Assessments (DPIAs) are mandatory under GDPR Article 35 for high-risk processing. AI systems almost always trigger this requirement.
When DPIAs Are Mandatory
- Systematic and extensive automated decision-making with legal/significant effects
- Large-scale processing of sensitive data categories
- Systematic monitoring of publicly accessible areas
- New technologies with high privacy risks (most AI qualifies)
AI-Specific DPIA Components
1. Training Data Assessment
Document data sources, collection methods, and legal basis:
# Training Data Provenance Tracker
class TrainingDataAudit:
def __init__(self, dataset_id):
self.dataset_id = dataset_id
self.records = []
def log_data_source(self, source, legal_basis, consent_ids=None):
"""Track legal basis for each data source"""
record = {
"timestamp": datetime.now(),
"source": source,
"legal_basis": legal_basis, # consent, contract, legitimate_interest
"consent_ids": consent_ids or [],
"data_subjects": self.count_data_subjects(source),
"sensitive_categories": self.identify_sensitive_data(source),
"retention_period": self.get_retention_policy(legal_basis)
}
self.records.append(record)
# Flag for review if sensitive data without explicit consent
if record["sensitive_categories"] and legal_basis != "consent":
self.flag_for_legal_review(record)
def generate_pia_documentation(self):
"""Generate DPIA-compliant documentation"""
return {
"dataset_id": self.dataset_id,
"total_data_subjects": sum(r["data_subjects"] for r in self.records),
"legal_bases": self.summarize_legal_bases(),
"sensitive_data_handling": self.document_sensitive_processing(),
"retention_compliance": self.verify_retention_policies(),
"cross_border_transfers": self.identify_transfers(),
"risk_mitigation": self.document_safeguards()
}
def summarize_legal_bases(self):
"""Aggregate legal bases for transparency"""
bases = {}
for record in self.records:
basis = record["legal_basis"]
bases[basis] = bases.get(basis, 0) + record["data_subjects"]
return bases
def identify_transfers(self):
"""Track cross-border data flows"""
transfers = []
for record in self.records:
if record["source"].get("location") != "EU":
transfers.append({
"source": record["source"]["name"],
"location": record["source"]["location"],
"safeguard": self.get_transfer_mechanism(record["source"]),
"adequacy_decision": self.check_adequacy(record["source"]["location"])
})
return transfers
2. Feature Selection Privacy Review
Analyze whether features introduce discrimination or excessive inference risks:
- Protected characteristics: Race, gender, religion, health status
- Proxy variables: ZIP code (proxies for race/income), first names (proxies for ethnicity)
- Inference risks: Can the model infer sensitive attributes not explicitly provided?
Example violation: A hiring AI trained on historical data that included employee tenure. Tenure correlated with gender due to past discrimination, causing the model to discriminate against women despite gender not being a direct feature.
3. Model Explainability Requirements
GDPR Article 22 and EU AI Act require "right to explanation" for automated decisions:
Acceptable explanation methods:
- SHAP (SHapley Additive exPlanations) values for feature importance
- LIME (Local Interpretable Model-agnostic Explanations)
- Attention visualization for transformer models
- Counterfactual explanations (what would need to change for different outcome)
Implementation example:
import shap
class ExplainableAISystem:
def __init__(self, model):
self.model = model
self.explainer = shap.Explainer(model)
def make_decision_with_explanation(self, input_data, data_subject_id):
"""Generate decision with GDPR-compliant explanation"""
# Make prediction
prediction = self.model.predict(input_data)
# Generate explanation
shap_values = self.explainer(input_data)
# Log decision for audit trail
explanation_record = {
"data_subject_id": data_subject_id,
"timestamp": datetime.now(),
"decision": prediction[0],
"confidence": self.model.predict_proba(input_data)[0],
"top_factors": self.get_top_factors(shap_values),
"human_review_required": self.confidence_below_threshold(prediction)
}
self.log_decision(explanation_record)
# Return decision with explanation
return {
"decision": prediction[0],
"explanation": self.generate_human_readable_explanation(shap_values),
"right_to_object": True, # GDPR Article 21
"human_review_available": True # EU AI Act requirement
}
def generate_human_readable_explanation(self, shap_values):
"""Convert SHAP values to plain language"""
top_features = self.get_top_factors(shap_values, n=3)
explanation = f"This decision was primarily based on: "
for i, (feature, impact) in enumerate(top_features, 1):
direction = "increased" if impact > 0 else "decreased"
explanation += f"{i}) {feature} {direction} the likelihood"
explanation += ". You have the right to request human review of this decision."
return explanation
4. Data Minimization Assessment
Demonstrate that you process only data necessary for the specific purpose:
- Document why each feature is necessary
- Implement feature selection techniques that prioritize privacy
- Use techniques like differential privacy to limit individual data influence
DPIA Approval and Documentation
Required documentation:
- Systematic description of processing operations and purposes
- Assessment of necessity and proportionality
- Assessment of risks to data subjects
- Measures to address risks (technical and organizational)
- Consultation with Data Protection Officer (DPO)
- Review and approval process
Retention: Maintain DPIAs throughout the system's lifecycle and update when processing changes significantly.
Technical Implementation: Privacy-Preserving ML
Compliance isn't just documentation—it requires privacy-preserving technical implementation.
Differential Privacy
Add calibrated noise to prevent identifying individual training data:
import numpy as np
from diffprivlib.models import LogisticRegression
class DifferentiallyPrivateModel:
def __init__(self, epsilon=1.0):
"""
Initialize with privacy budget epsilon
Lower epsilon = stronger privacy, lower accuracy
Typical range: 0.1 (strong privacy) to 10 (weak privacy)
"""
self.epsilon = epsilon
self.model = LogisticRegression(epsilon=epsilon)
def train(self, X, y):
"""Train with differential privacy guarantees"""
self.model.fit(X, y)
# Document privacy parameters for compliance
self.privacy_record = {
"epsilon": self.epsilon,
"delta": 1e-5, # Probability of privacy breach
"privacy_accountant": "Differential Privacy",
"noise_mechanism": "Laplace",
"training_samples": len(X),
"privacy_budget_consumed": self.epsilon
}
def predict(self, X):
return self.model.predict(X)
def get_privacy_documentation(self):
"""Generate privacy guarantees for DPIA"""
return {
**self.privacy_record,
"guarantee": f"ε-differential privacy with ε={self.epsilon}",
"interpretation": f"Any individual's data changes output probability by at most {np.exp(self.epsilon):.2f}x",
"compliance_note": "Differential privacy provides formal privacy guarantees for GDPR data minimization"
}
When to use: Differential privacy is critical for:
- Training data from sensitive populations (health, financial)
- High-risk systems under EU AI Act
- Scenarios where re-identification risk is high
Trade-off: Privacy comes at accuracy cost. Benchmark shows 2-5% accuracy degradation typical at ε=1.0.
Federated Learning
Train models without centralizing data:
Architecture:
Hospital A (Local Data) ────┐
├──→ Aggregation Server (Model Updates Only)
Hospital B (Local Data) ────┤ ↓
│ Global Model
Hospital C (Local Data) ────┘
Benefits:
- Data never leaves local environment (data sovereignty compliance)
- Reduces GDPR transfer obligations
- Enables multi-party training without data sharing agreements
Limitations:
- Requires coordinated infrastructure across parties
- Communication overhead can be significant
- Still vulnerable to some inference attacks (mitigated with secure aggregation)
PII Detection and Redaction
Automatically identify and handle personally identifiable information:
import re
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
class PIIHandler:
def __init__(self):
self.analyzer = AnalyzerEngine()
self.anonymizer = AnonymizerEngine()
def detect_pii(self, text):
"""Identify PII in unstructured text"""
results = self.analyzer.analyze(
text=text,
language='en',
entities=[
"PERSON", "EMAIL_ADDRESS", "PHONE_NUMBER",
"CREDIT_CARD", "IBAN_CODE", "IP_ADDRESS",
"LOCATION", "DATE_TIME", "MEDICAL_LICENSE"
]
)
return results
def anonymize_for_training(self, text):
"""Redact PII before using in training data"""
pii_results = self.detect_pii(text)
anonymized = self.anonymizer.anonymize(
text=text,
analyzer_results=pii_results,
operators={
"PERSON": {"type": "replace", "new_value": "<PERSON>"},
"EMAIL_ADDRESS": {"type": "replace", "new_value": "<EMAIL>"},
"PHONE_NUMBER": {"type": "mask"},
"CREDIT_CARD": {"type": "replace", "new_value": "<CREDIT_CARD>"},
"LOCATION": {"type": "replace", "new_value": "<LOCATION>"}
}
)
# Log anonymization for audit
self.log_anonymization({
"timestamp": datetime.now(),
"pii_detected": len(pii_results),
"pii_types": [r.entity_type for r in pii_results],
"anonymization_method": "replacement"
})
return anonymized.text
def pseudonymize_with_key(self, text, encryption_key):
"""Reversible pseudonymization for regulated environments"""
# Use for scenarios where re-identification may be necessary
# (e.g., medical research with ethics board approval)
pii_results = self.detect_pii(text)
pseudonymized = self.anonymizer.anonymize(
text=text,
analyzer_results=pii_results,
operators={
"PERSON": {"type": "encrypt", "key": encryption_key},
"EMAIL_ADDRESS": {"type": "encrypt", "key": encryption_key}
}
)
return pseudonymized.text
GDPR distinction:
- Anonymization: Irreversible, data no longer subject to GDPR
- Pseudonymization: Reversible with key, still subject to GDPR but reduces risk
Consent Management for AI Systems
GDPR requires explicit, informed, freely given consent for most AI processing. Implementing compliant consent is complex.
Consent Requirements
Valid consent must be:
- Freely given: No imbalance of power, no conditional service access
- Specific: Separate consent for each distinct purpose
- Informed: Clear explanation of what data is used and how
- Unambiguous: Affirmative action required (no pre-ticked boxes)
- Withdrawable: Easy to revoke consent at any time
Consent Mode v2 Implementation
Google's Consent Mode v2 (required for EU sites in 2024+) provides template for AI consent:
// Consent Management for AI Features
class AIConsentManager {
constructor() {
this.consentState = {
aiPersonalization: null,
aiAnalytics: null,
aiRecommendations: null,
aiDataSharing: null
};
}
async requestConsent(userId) {
// Present granular consent options
const consent = await this.showConsentUI({
purposes: [
{
id: 'aiPersonalization',
title: 'AI-Powered Personalization',
description: 'Use your browsing history and preferences to train AI models that customize your experience',
dataUsed: ['browsing history', 'search queries', 'click patterns'],
retentionPeriod: '24 months',
thirdPartySharing: false
},
{
id: 'aiAnalytics',
title: 'AI Analytics',
description: 'Analyze your usage patterns to improve our AI features',
dataUsed: ['interaction data', 'session duration', 'feature usage'],
retentionPeriod: '12 months',
thirdPartySharing: false
},
{
id: 'aiRecommendations',
title: 'AI Recommendations',
description: 'Generate personalized content and product recommendations',
dataUsed: ['purchase history', 'ratings', 'saved items'],
retentionPeriod: '36 months',
thirdPartySharing: true,
thirdParties: ['Recommendation API Provider']
}
],
allowGranular: true, // Must allow separate consent per purpose
rejectAllOption: true, // GDPR requires easy rejection
withdrawalProcess: 'Settings > Privacy > AI Features'
});
// Store consent record
await this.storeConsent(userId, consent);
return consent;
}
async storeConsent(userId, consent) {
// Maintain audit trail
const record = {
userId: userId,
timestamp: new Date().toISOString(),
consentVersion: '2.0', // Track consent text version
consents: consent,
ipAddress: this.getHashedIP(), // Hashed for privacy
userAgent: this.getUserAgent(),
method: 'explicit_opt_in'
};
await this.database.consentRecords.insert(record);
// Update consent state for this session
this.consentState = consent;
}
async withdrawConsent(userId, purposes) {
// GDPR Article 7(3): Must be as easy to withdraw as to give
await this.database.consentRecords.update(
{ userId: userId },
{
$set: {
withdrawnAt: new Date().toISOString(),
withdrawnPurposes: purposes
}
}
);
// Trigger data deletion pipeline
await this.initiateDataDeletion(userId, purposes);
return { success: true, deletionInitiated: true };
}
async initiateDataDeletion(userId, purposes) {
// GDPR Article 17: Right to erasure
// Delete training data derived from withdrawn purposes
const deletionJob = {
userId: userId,
purposes: purposes,
status: 'pending',
requestedAt: new Date().toISOString(),
completionDeadline: this.calculateDeadline(30) // 30 days max
};
await this.queue.push('data-deletion', deletionJob);
}
}
Dark Patterns to Avoid
Recent GDPR enforcement actions target manipulative consent UI:
Prohibited patterns:
- Making rejection significantly harder than acceptance (extra clicks, hidden options)
- Using confusing language or double negatives
- Pre-ticked boxes or implied consent
- Blocking access to service for rejecting non-essential processing
- Nudging toward acceptance with visual design (bright "Accept" vs gray "Reject")
Example fine: €90 million fine to a tech company in Q1 2025 for making cookie rejection require 5 clicks vs 1 click for acceptance.
Cross-Border Data Flows
AI training and inference often involve cross-border data transfers, triggering GDPR Chapter V requirements.
Transfer Mechanisms
1. Adequacy Decisions EU determines certain countries provide "adequate" protection:
- Current adequate countries: UK, Switzerland, Japan, Canada (commercial), South Korea
- Transfers to adequate countries require no additional safeguards
2. Standard Contractual Clauses (SCCs) EU-approved contract templates for transfers to non-adequate countries:
- Must complete Transfer Impact Assessment (TIA)
- Document that destination country laws don't undermine protections
- Implement supplementary measures if needed (encryption, pseudonymization)
3. Binding Corporate Rules (BCRs) Internal policies for multinational companies:
- Requires approval from lead Data Protection Authority
- Takes 12-18 months to approve typically
- Useful for frequent intra-company transfers
AI-Specific Transfer Challenges
Cloud ML platforms: Many use distributed infrastructure, data may be processed in multiple jurisdictions
Solution: Configure region-specific deployments:
# Region-locked AI deployment configuration
ai_deployment_config = {
"eu_customers": {
"training_region": "eu-west-1",
"inference_region": "eu-west-1",
"data_residency": "EU_ONLY",
"transfer_mechanism": None, # No transfer required
"model_registry": "https://eu-models.example.com"
},
"us_customers": {
"training_region": "us-east-1",
"inference_region": "us-east-1",
"data_residency": "US_ONLY",
"transfer_mechanism": None
},
"global_customers": {
"training_region": "eu-west-1", # EU for GDPR compliance
"inference_region": "multi-region",
"data_residency": "FEDERATED",
"transfer_mechanism": "Standard Contractual Clauses",
"transfer_impact_assessment": "TIA-2026-001",
"supplementary_measures": ["encryption-in-transit", "encryption-at-rest", "pseudonymization"]
}
}
Vendor contracts: Ensure SaaS AI providers (OpenAI, Anthropic, Google) have appropriate transfer mechanisms in place
Required contract terms:
- Data processing agreement (DPA) with SCCs
- Data residency guarantees if needed
- Sub-processor notification and approval rights
- Audit rights for compliance verification
Records of Processing Activities (ROPA)
GDPR Article 30 requires maintaining comprehensive records of all processing activities. AI systems require enhanced documentation.
AI-Specific ROPA Elements
For each AI system, document:
1. System identification
- Name and purpose of AI system
- Legal basis for processing (consent, contract, legitimate interest, legal obligation)
- Data controller and processor identities
2. Data inventory
- Categories of data subjects (customers, employees, etc.)
- Categories of personal data processed
- Special category data (health, biometric, etc.)
- Data sources (direct collection, third parties, public sources)
3. Processing operations
- Training data preparation and curation
- Model training and validation
- Inference and prediction
- Output storage and retention
- Monitoring and retraining
4. Retention and deletion
- Retention periods for training data
- Retention periods for model outputs
- Deletion procedures when retention expires
- Right to erasure implementation
5. Security measures
- Access controls (who can train models, access training data)
- Encryption (data at rest, in transit)
- Audit logging
- Incident response procedures
6. International transfers
- Countries data is transferred to
- Transfer mechanisms (SCCs, adequacy, BCRs)
- Transfer impact assessments
Automation opportunity: Generate ROPA automatically from deployment configurations
class AutomatedROPA:
def generate_ropa_entry(self, ai_system_config):
"""Generate GDPR Article 30 record from system config"""
return {
"system_name": ai_system_config["name"],
"data_controller": {
"name": ai_system_config["organization"],
"contact": ai_system_config["dpo_contact"],
"representative": ai_system_config.get("eu_representative")
},
"purposes": ai_system_config["processing_purposes"],
"legal_basis": self.determine_legal_basis(ai_system_config),
"data_categories": self.extract_data_categories(ai_system_config),
"data_subjects": ai_system_config["data_subject_categories"],
"recipients": self.identify_recipients(ai_system_config),
"international_transfers": self.document_transfers(ai_system_config),
"retention_periods": ai_system_config["retention"],
"security_measures": self.document_security(ai_system_config),
"dpia_reference": ai_system_config.get("dpia_id"),
"last_updated": datetime.now().isoformat()
}
Compliance Checklist
Use this checklist before deploying AI systems in GDPR or CCPA jurisdictions:
Pre-Deployment (30-60 days before launch)
- [ ] Legal basis determined for all processing operations
- [ ] DPIA completed and approved by DPO
- [ ] Training data audit documenting sources and legal basis
- [ ] Feature privacy review excluding protected characteristics and proxies
- [ ] Consent mechanism implemented if consent is legal basis
- [ ] Model explainability implemented for automated decisions
- [ ] Transfer impact assessment completed if cross-border transfers
- [ ] Vendor contracts include DPAs and SCCs
- [ ] Security measures documented and implemented
- [ ] Incident response procedures established
- [ ] ROPA entry created and maintained
- [ ] Privacy notice updated to reflect AI processing
- [ ] User rights procedures tested (access, erasure, portability, objection)
EU AI Act Specific (if high-risk system)
- [ ] Risk classification documented with justification
- [ ] Technical documentation prepared per Annex IV requirements
- [ ] Quality management system established
- [ ] Conformity assessment completed by notified body (if required)
- [ ] EU database registration submitted
- [ ] Human oversight mechanisms implemented
- [ ] Accuracy, robustness, cybersecurity requirements met
- [ ] Transparency obligations fulfilled (AI disclosure to users)
- [ ] Record-keeping systems operational
Ongoing Operations
- [ ] Quarterly model monitoring for accuracy and bias
- [ ] Annual DPIA review and updates
- [ ] Data subject requests handled within 30 days (GDPR) or 45 days (CCPA)
- [ ] Breach notification procedures tested
- [ ] Training data refresh reviewed for compliance
- [ ] Vendor audits conducted annually
- [ ] Regulatory updates monitored and implemented
Enforcement Case Studies
Learn from recent enforcement actions:
Case 1: Inadequate Training Data Legal Basis
Company: European e-commerce retailer Fine: €65 million Violation: Used customer purchase data to train recommendation AI under "legitimate interests" without proper balancing test Lesson: Legitimate interests requires documented balancing test showing your interests don't override data subject rights. For AI training, consent or contractual necessity are safer legal bases.
Case 2: Insufficient Explainability
Company: Fintech lender Fine: €12 million Violation: Automated loan rejections without meaningful explanation, violating GDPR Article 22 Lesson: SHAP values and technical metrics aren't sufficient—explanations must be understandable to average person.
Case 3: Cross-Border Transfer Without Safeguards
Company: HR tech company Fine: €8 million Violation: Transferred employee data to U.S. for AI training without SCCs or TIA Lesson: After Schrems II, transfers to U.S. require not just SCCs but also TIA and supplementary measures.
Case 4: Dark Pattern Consent
Company: Social media platform Fine: €90 million Violation: Made accepting AI-powered advertising one click but rejecting required navigating five screens Lesson: Consent must be as easy to withdraw/reject as to give.
Future Regulatory Developments
Expect these compliance requirements in 2026-2027:
Q3 2026: EU AI Act fully in force, enforcement begins for high-risk systems Q4 2026: GDPR guidance on AI training data expected from European Data Protection Board 2027: U.S. federal privacy law anticipated (would preempt some state laws) 2027: California CPRA amendments for AI-specific requirements take effect
Emerging requirements to monitor:
- Mandatory algorithmic impact assessments (similar to DPIAs but bias-focused)
- AI system registration and public disclosure databases
- Enhanced explainability requirements for credit, employment, housing
- Restrictions on emotion recognition and biometric categorization
Getting Started
Week 1-2: Assessment
- Inventory all AI systems in production or development
- Classify each by risk level (GDPR DPIA required? EU AI Act high-risk?)
- Identify gaps in current compliance posture
Week 3-4: Documentation
- Complete or update DPIAs for each system
- Create/update ROPA entries
- Document training data legal basis
Week 5-8: Technical Implementation
- Implement explainability for automated decisions
- Deploy PII detection and redaction
- Configure region-specific deployments for data residency
Week 9-12: Processes
- Establish data subject request handling procedures
- Create breach notification playbooks
- Set up quarterly monitoring and review cycles
Ongoing:
- Monitor regulatory developments
- Conduct annual vendor audits
- Retrain compliance team on updates
Conclusion
Data privacy compliance for AI systems is complex but achievable with systematic implementation. The August 2026 EU AI Act deadline makes this work urgent for organizations deploying high-risk systems.
Focus on these priorities:
- Determine legal basis for all training data and processing operations
- Implement explainability for automated decisions
- Document everything in DPIAs and ROPAs
- Test user rights procedures before you need them under pressure
- Monitor regulatory updates aggressively—guidance is still evolving
Organizations that build privacy into AI systems from the start avoid expensive retrofitting and enforcement actions. With GDPR fines averaging €2.4 million and EU AI Act penalties reaching 7% of global turnover, compliance is a business-critical investment.
Additional Resources
- Complete GDPR Compliance Guide 2026
- Privacy Laws 2026: Global Updates and Requirements
- GDPR and AI 2026: Rules, Risks, and Compliant Tools
- Data Protection Strategies for 2026
- AI and Personal Data Protection: GDPR & CCPA Compliance
- EU AI Act Official Text
- GDPR Official Text
- EDPB Guidelines on Automated Decision-Making
- NIST AI Risk Management Framework
Implementing privacy-preserving AI systems? Explore our related guides on AI Governance and Security Production 2026 and Building Production-Ready LLM Applications.


