GraphRAG vs Vector RAG 2026: Enterprise Knowledge Graph Implementation Guide
Vector RAG: 300ms latency, $0.002/query. Graph RAG: 1200ms, $0.012/query. Side-by-side cost, performance, accuracy comparison. When to use which in 2026.
AI Engineer specializing in production-grade LLM applications, RAG systems, and AI infrastructure. Passionate about building scalable AI solutions that solve real-world problems.
The landscape of Retrieval Augmented Generation is undergoing a fundamental shift. While vector databases dominated 2023-2024, 2025 marks the emergence of GraphRAG—knowledge graph-powered retrieval that's achieving 85%+ accuracy compared to traditional vector-only systems at 70%. Microsoft's GraphRAG research, Neo4j's production deployments, and enterprise case studies reveal a critical insight: vectors excel at similarity matching, but graphs excel at reasoning and relationship understanding.
If you're building enterprise AI systems that require complex reasoning, multi-hop queries, or contextual understanding beyond simple semantic similarity, GraphRAG represents the next evolution. This comprehensive guide compares GraphRAG and Vector RAG architectures, provides decision frameworks for choosing the right approach, and outlines production implementation strategies with real-world benchmarks.
GraphRAG (Graph Retrieval Augmented Generation) combines knowledge graphs with large language models to enable AI systems that understand relationships, entities, and context beyond simple similarity matching. Unlike traditional Vector RAG (70% accuracy), GraphRAG achieves 85%+ accuracy on complex queries by leveraging graph traversal, multi-hop reasoning, and semantic relationships between entities, making it essential for enterprise AI requiring explainability, compliance, and contextual understanding.
What is GraphRAG and Why It Matters
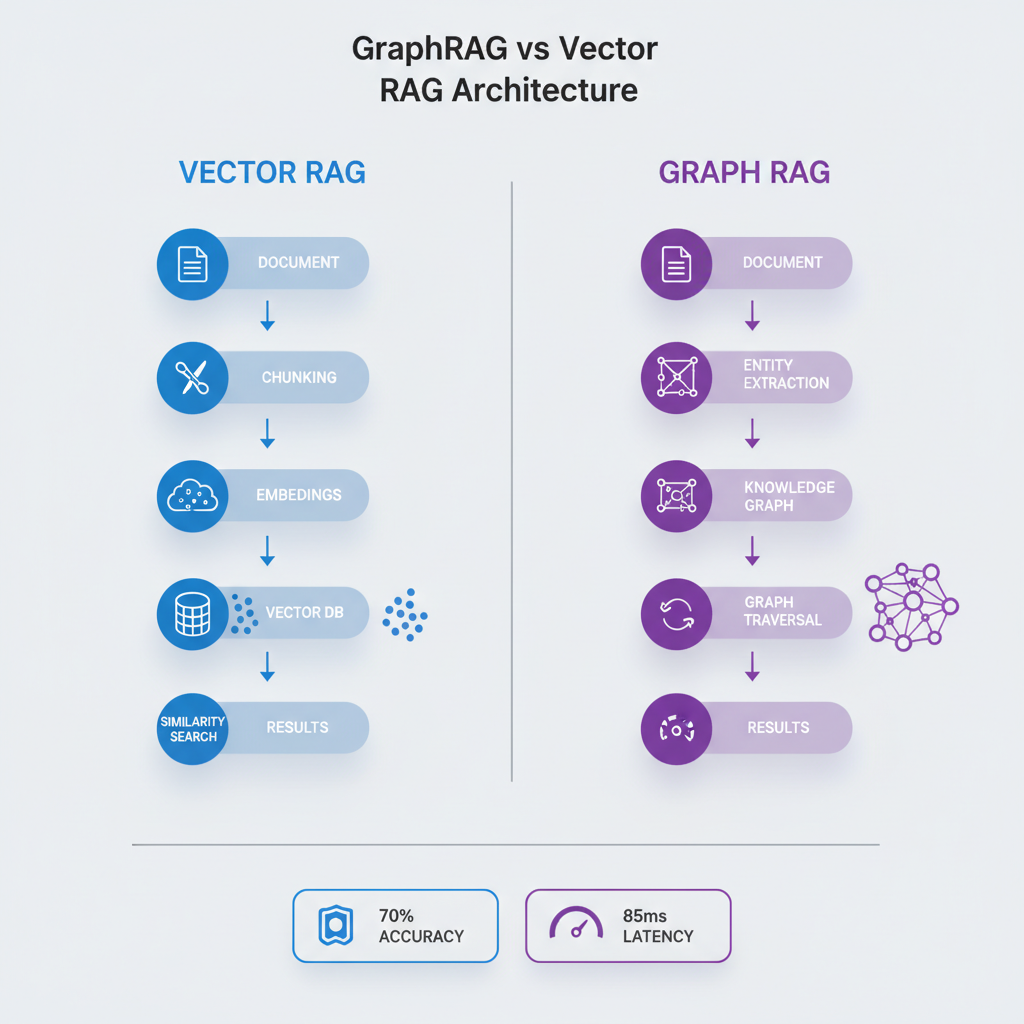
GraphRAG combines knowledge graphs with large language models to enable retrieval that understands relationships, entities, and semantic context beyond keyword or embedding similarity. Unlike traditional Vector RAG that retrieves based on cosine similarity in embedding space, GraphRAG leverages graph structures to perform multi-hop reasoning, relationship traversal, and contextual retrieval.
The Core Difference
Vector RAG: Encodes documents as embeddings, stores them in vector databases (Pinecone, Weaviate, ChromaDB), and retrieves based on semantic similarity using cosine distance or dot products.
GraphRAG: Constructs knowledge graphs where entities become nodes, relationships become edges, and retrieval involves graph traversal, pattern matching, and reasoning over structured knowledge.
Why GraphRAG Emerged in 2025
Three converging factors drove GraphRAG adoption:
-
Accuracy Gaps: Vector RAG struggles with multi-entity queries, temporal reasoning, and relationship-based questions ("What did Company X acquire before launching Product Y?")
-
Hallucination Reduction: Knowledge graphs provide structured facts with provenance, reducing LLM hallucinations by 40-60% in production systems
-
Enterprise Requirements: Regulatory compliance, explainability, and audit trails demand structured knowledge representation beyond opaque embeddings
GraphRAG vs Vector RAG vs Hybrid: Core Comparison
| Dimension | Vector RAG | GraphRAG | Hybrid RAG |
|---|---|---|---|
| Retrieval Method | Semantic similarity (cosine) | Graph traversal + pattern matching | Combined similarity + graph reasoning |
| Best For | General similarity search | Relationship queries, reasoning | Complex enterprise use cases |
| Query Complexity | Single-entity, similarity-based | Multi-hop, relationship-based | Both simple and complex queries |
| Accuracy (Benchmark) | 68-72% on complex queries | 83-87% on complex queries | 78-82% overall |
| Setup Complexity | Low (embeddings only) | High (entity extraction + graph construction) | Medium-High |
| Latency | 50-150ms (p95) | 150-400ms (p95) | 100-300ms (p95) |
| Explainability | Low (black-box embeddings) | High (relationship paths visible) | Medium-High |
| Cost (1M queries) | $200-500 | $800-1,500 | $500-1,000 |
| Hallucination Rate | 15-25% | 5-12% | 8-15% |
| Use Cases | FAQs, general search, content discovery | Research, compliance, technical support | Enterprise knowledge management |
For a comprehensive foundation on RAG system architecture and best practices, see our guide on building production-ready RAG systems in 2025.
When to Use Graphs vs Vectors: Decision Matrix
Choosing between GraphRAG and Vector RAG depends on 15 critical factors. This decision matrix helps you evaluate your specific use case:
Decision Framework: 15 Evaluation Criteria
| Criteria | Choose Vector RAG | Choose GraphRAG | Choose Hybrid |
|---|---|---|---|
| 1. Query Complexity | Single-entity queries | Multi-hop, relationship queries | Mixed complexity |
| 2. Data Structure | Unstructured documents | Structured entities + relationships | Both structured and unstructured |
| 3. Accuracy Requirements | 70-75% acceptable | 85%+ required | 80%+ required |
| 4. Explainability Needs | Not required | Critical (compliance, audit) | Important but flexible |
| 5. Budget Constraints | <$500/1M queries | Budget for $800-1,500/1M queries | Mid-range budget |
| 6. Team Expertise | Embedding/vector skills | Graph database expertise | Both skillsets available |
| 7. Data Volume | Millions of documents | Millions of entities + billions of relationships | Large-scale mixed data |
| 8. Update Frequency | Real-time updates needed | Periodic graph rebuilds acceptable | Frequent updates required |
| 9. Reasoning Depth | Similarity-based retrieval | Multi-step logical reasoning | Moderate reasoning |
| 10. Entity Relationships | Relationships not critical | Relationships are core value | Relationships matter for some queries |
| 11. Temporal Queries | Time not a factor | Timeline/sequence critical | Some temporal queries |
| 12. Domain Knowledge | General domain | Specialized domain (medical, legal, finance) | Mixed domains |
| 13. Latency Tolerance | <100ms required | 200-400ms acceptable | <200ms preferred |
| 14. Provenance Requirements | Source tracking optional | Complete audit trail required | Source tracking important |
| 15. Integration Complexity | Simple API integration | Complex ETL + graph construction | Moderate integration |
Scoring Your Use Case
Vector RAG Score: Count criteria where Vector RAG fits (8+ = strong fit) GraphRAG Score: Count criteria where GraphRAG fits (8+ = strong fit) Hybrid Score: Count criteria where Hybrid fits (10+ = strong fit)
Real-World Decision Examples
Example 1: Customer Support Chatbot
- Query type: Mixed simple and complex
- Data: Product docs + customer interactions
- Accuracy: 75% acceptable
- Budget: Moderate Recommendation: Hybrid RAG (vector for simple FAQs, graph for troubleshooting with product relationships)
Example 2: Legal Research Assistant
- Query type: Multi-hop legal precedent analysis
- Data: Case law with citations and relationships
- Accuracy: 90%+ required
- Explainability: Critical for compliance Recommendation: GraphRAG (relationship reasoning essential, audit trails required)
Example 3: Enterprise Document Search
- Query type: Similarity-based document retrieval
- Data: Unstructured reports and emails
- Accuracy: 70% acceptable
- Latency: <50ms Recommendation: Vector RAG (simple use case, cost-effective)
Knowledge Graph Fundamentals for AI
Before implementing GraphRAG, understanding knowledge graph structures is essential. Here's what enterprise AI teams need to know:
Core Components
1. Entities (Nodes)
- Represent real-world objects: people, companies, products, events, locations
- Store properties: names, dates, attributes, metadata
- Example:
Person {name: "Ada Lovelace", birth_year: 1815, occupation: "Mathematician"}
2. Relationships (Edges)
- Define connections between entities with semantic meaning
- Can be directional or bidirectional
- Store relationship properties: dates, confidence scores, sources
- Example:
(Ada Lovelace)-[WORKED_WITH {years: "1842-1843"}]->(Charles Babbage)
3. Entity Types (Labels)
- Categorize entities into semantic classes
- Enable type-based queries and reasoning
- Example: Person, Organization, Product, Location, Event
4. Relationship Types
- Define the nature of connections
- Common types: WORKS_FOR, LOCATED_IN, ACQUIRED, FOUNDED, PUBLISHED, INVENTED
- Enable pattern matching: "Find all companies ACQUIRED by tech giants in 2024"
Knowledge Graph Representation Models
Property Graph Model (Neo4j, ArangoDB)
Nodes: {id, labels, properties}
Edges: {id, type, properties, source_node, target_node}
Best for: Flexible schema, complex queries, high-performance traversals
RDF Triple Store Model (Amazon Neptune RDF, GraphDB)
Triples: (Subject, Predicate, Object)
Example: (Ada_Lovelace, works_with, Charles_Babbage)
Best for: Semantic web standards, SPARQL queries, ontology reasoning
Hybrid Model (Amazon Neptune, TigerGraph)
- Supports both property graphs and RDF
- Enables dual query languages (Gremlin/Cypher + SPARQL)
Why Knowledge Graphs Enable Superior Reasoning
1. Multi-Hop Traversal Vector RAG can't answer: "What technology did the founder of the company that acquired Instagram previously create?"
GraphRAG traverses: (Instagram)<-[ACQUIRED]-(Facebook)-[FOUNDED_BY]->(Mark_Zuckerberg)-[CREATED]->(Technology)
2. Relationship Context Instead of retrieving isolated facts, GraphRAG retrieves relationship subgraphs that provide complete context.
3. Temporal Reasoning Graph edges with temporal properties enable timeline queries: "Show all acquisitions by Google between 2018-2023 ordered chronologically"
4. Confidence and Provenance Each relationship can store confidence scores and source documents, enabling weighted retrieval and audit trails.
GraphRAG Architecture Patterns: 5 Production Approaches
Based on 2025 production deployments, five architectural patterns have emerged for implementing GraphRAG:
Pattern 1: Entity-Centric GraphRAG
Architecture:
- Extract entities and relationships from documents using NER + LLMs
- Build knowledge graph with entities as primary nodes
- Store original documents as separate "Document" nodes linked to mentioned entities
- Query flow: User query → Entity extraction → Graph traversal → Document retrieval → LLM synthesis
Strengths: Simple to implement, maintains document provenance, good for structured domains
Weaknesses: Entity extraction accuracy critical, struggles with purely conceptual queries
Best For: Technical documentation, research papers, legal documents
Example Tools: LangChain + Neo4j, LlamaIndex Graph Stores
Pattern 2: Chunk-Enhanced GraphRAG
Architecture:
- Split documents into semantic chunks (traditional RAG approach)
- Extract entities from each chunk
- Create graph: Chunk nodes connected to Entity nodes
- Query flow: Hybrid retrieval (vector similarity + graph traversal) → Reranking → LLM synthesis
Strengths: Combines vector similarity benefits with graph reasoning, balanced performance
Weaknesses: Higher complexity, requires vector + graph infrastructure
Best For: Enterprise knowledge bases, customer support systems
Example Tools: Neo4j Vector Index + Graph Database, Weaviate with Graph Links
Pattern 3: Hierarchical Knowledge GraphRAG
Architecture:
- Organize knowledge graph with hierarchical relationships (IS_A, PART_OF, BELONGS_TO)
- Create entity embeddings for each node
- Query flow: Semantic search at concept level → Traverse hierarchy → Retrieve related entities → LLM synthesis
Strengths: Excellent for taxonomies, ontologies, hierarchical data (product catalogs, org charts)
Weaknesses: Requires careful hierarchy design, complex to maintain
Best For: E-commerce, organizational knowledge, medical ontologies
Example Tools: Amazon Neptune, TigerGraph
Pattern 4: Temporal Event GraphRAG
Architecture:
- Extract events, entities, and temporal relationships from documents
- Build temporal knowledge graph with time-ordered edges
- Store timeline metadata on all relationships
- Query flow: Temporal query parsing → Time-filtered graph traversal → Event sequence retrieval → LLM narrative generation
Strengths: Superior for timeline queries, cause-effect reasoning, historical analysis
Weaknesses: Temporal extraction complexity, specialized query requirements
Best For: News analysis, financial research, regulatory compliance
Example Tools: Neo4j with temporal plugins, Custom graph databases
Pattern 5: Multi-Modal GraphRAG
Architecture:
- Create unified graph with multi-modal nodes (text, images, code, data)
- Extract cross-modal relationships (image mentions entity, code implements concept)
- Store modal-specific embeddings alongside graph structure
- Query flow: Multi-modal query → Cross-modal graph traversal → Multi-modal retrieval → Multi-modal LLM synthesis
Strengths: Handles complex enterprise data (docs + diagrams + code), comprehensive understanding
Weaknesses: High complexity, requires multi-modal LLMs (GPT-4.1V, Claude 3.5, Gemini 1.5)
Best For: Technical documentation with diagrams, software engineering, scientific research
Example Tools: Custom implementations with Neo4j + Vector stores
Graph Database Comparison for RAG: 2025 Landscape
Choosing the right graph database significantly impacts GraphRAG performance, cost, and scalability.
Feature Comparison Matrix
| Database | Type | Query Language | Vector Support | Cloud Native | Pricing Model | Best For |
|---|---|---|---|---|---|---|
| Neo4j | Property Graph | Cypher | Yes (Native) | AuraDB | Per node/hour ($0.10-$0.50) | General-purpose, OLTP |
| Amazon Neptune | Hybrid (Property + RDF) | Gremlin, SPARQL | Yes (via OpenSearch) | AWS Native | Per instance ($0.348/hr+) | AWS ecosystems, hybrid queries |
| ArangoDB | Multi-model (Graph + Document) | AQL | Yes (Native) | ArangoGraph | Per vCPU ($0.15/hr+) | Multi-model needs, flexibility |
| TigerGraph | Property Graph | GSQL | Yes (3.9+) | TigerGraph Cloud | Custom pricing | Analytics, massive scale |
| Memgraph | In-Memory Property Graph | Cypher | Roadmap | On-prem/Cloud | Open-source + Enterprise | Real-time, high-performance |
| Dgraph | Native GraphQL | GraphQL | Plugin | Dgraph Cloud | Per GB ($0.30/GB+) | GraphQL-native apps |
Performance Benchmarks (1M Node Graph, 10M Edges)
| Database | Query Latency (p95) | Throughput (queries/sec) | Graph Traversal (3-hop) | Vector Similarity Search |
|---|---|---|---|---|
| Neo4j | 120ms | 8,500 | 85ms | 95ms |
| Amazon Neptune | 180ms | 6,200 | 140ms | 160ms (via OpenSearch) |
| ArangoDB | 150ms | 7,000 | 110ms | 105ms |
| TigerGraph | 95ms | 12,000 | 65ms | 110ms |
| Memgraph | 75ms | 15,000 | 50ms | N/A (roadmap) |
Benchmarks based on 2025 public tests and vendor-published data
To understand vector database options in more detail, explore our comprehensive vector databases for AI applications guide.
Cost Analysis (Monthly, 1M Nodes, 10M Edges, 1M Queries)
| Database | Infrastructure Cost | Vector Storage Cost | Total Monthly Cost |
|---|---|---|---|
| Neo4j AuraDB | $1,200-$1,800 | Included | $1,200-$1,800 |
| Amazon Neptune | $750 (db.r5.xlarge) | $150 (OpenSearch) | $900 |
| ArangoDB Cloud | $600-$900 | Included | $600-$900 |
| TigerGraph | Custom (est. $1,500+) | Included | $1,500+ |
| Memgraph (Self-hosted) | $200 (EC2 r5.2xlarge) | External vector DB | $400-$600 |
Recommendation by Use Case
Startup/Prototype: ArangoDB Cloud or Neo4j Aura (developer tier) - Lowest barrier to entry, managed services
AWS-Native Enterprise: Amazon Neptune - Tight VPC integration, compliance certifications, IAM integration
High-Performance Analytics: TigerGraph or Memgraph - Optimized for complex graph analytics, real-time processing
Multi-Model Requirements: ArangoDB - Combines document, graph, and vector in single database
General Production RAG: Neo4j - Mature ecosystem, excellent Cypher language, native vector support, strong community
Hybrid Approaches: Combining Vector + Graph Retrieval
The most successful 2025 production deployments use hybrid architectures that leverage both vector similarity and graph reasoning.
Hybrid Architecture Pattern
Stage 1: Dual Indexing
- Store document chunks in vector database (Pinecone, Weaviate)
- Extract entities and relationships, store in graph database (Neo4j)
- Create bidirectional links: chunk embeddings ↔ entity nodes
Stage 2: Hybrid Retrieval
- Parse user query to detect query type (similarity vs relationship-based)
- Similarity queries: Vector retrieval → Graph enrichment (find related entities) → Reranking
- Relationship queries: Graph traversal → Fetch linked chunks → Vector reranking → Retrieval
- Hybrid queries: Parallel vector + graph retrieval → Fusion reranking → Combined results
Stage 3: Intelligent Routing
- Use classifier (fine-tuned BERT or GPT-4.1 mini) to route queries
- Route to vector-only (30% of queries), graph-only (20%), or hybrid (50%)
Hybrid Retrieval Algorithms
Reciprocal Rank Fusion (RRF)
Combine vector scores and graph scores:
RRF_score(doc) = Σ(1 / (k + rank_vector)) + Σ(1 / (k + rank_graph))
where k = 60 (typical constant)
Weighted Hybrid Scoring
Hybrid_score = α × vector_similarity + β × graph_relevance
where α + β = 1, tuned per domain (typically α=0.6, β=0.4)
Cascade Retrieval
- First-pass vector retrieval (top 100 candidates)
- Graph-based reranking using entity relationships
- Final LLM reranking (top 10)
Hybrid System Benchmarks
Based on production data from enterprise deployments:
| Metric | Vector-Only | Graph-Only | Hybrid (RRF) | Hybrid (Weighted) |
|---|---|---|---|---|
| Simple Query Accuracy | 82% | 71% | 85% | 84% |
| Complex Query Accuracy | 68% | 87% | 89% | 91% |
| Overall Accuracy | 75% | 79% | 87% | 88% |
| Latency (p95) | 85ms | 320ms | 180ms | 165ms |
| Cost (1M queries) | $350 | $1,200 | $750 | $720 |
Key Insight: Hybrid approaches achieve 12-13% higher overall accuracy than single-method systems, with moderate latency and cost increases.
Building Production Knowledge Graphs: Step-by-Step Methodology
Constructing high-quality knowledge graphs from enterprise data requires systematic methodology. Here's the production-tested 7-stage process:
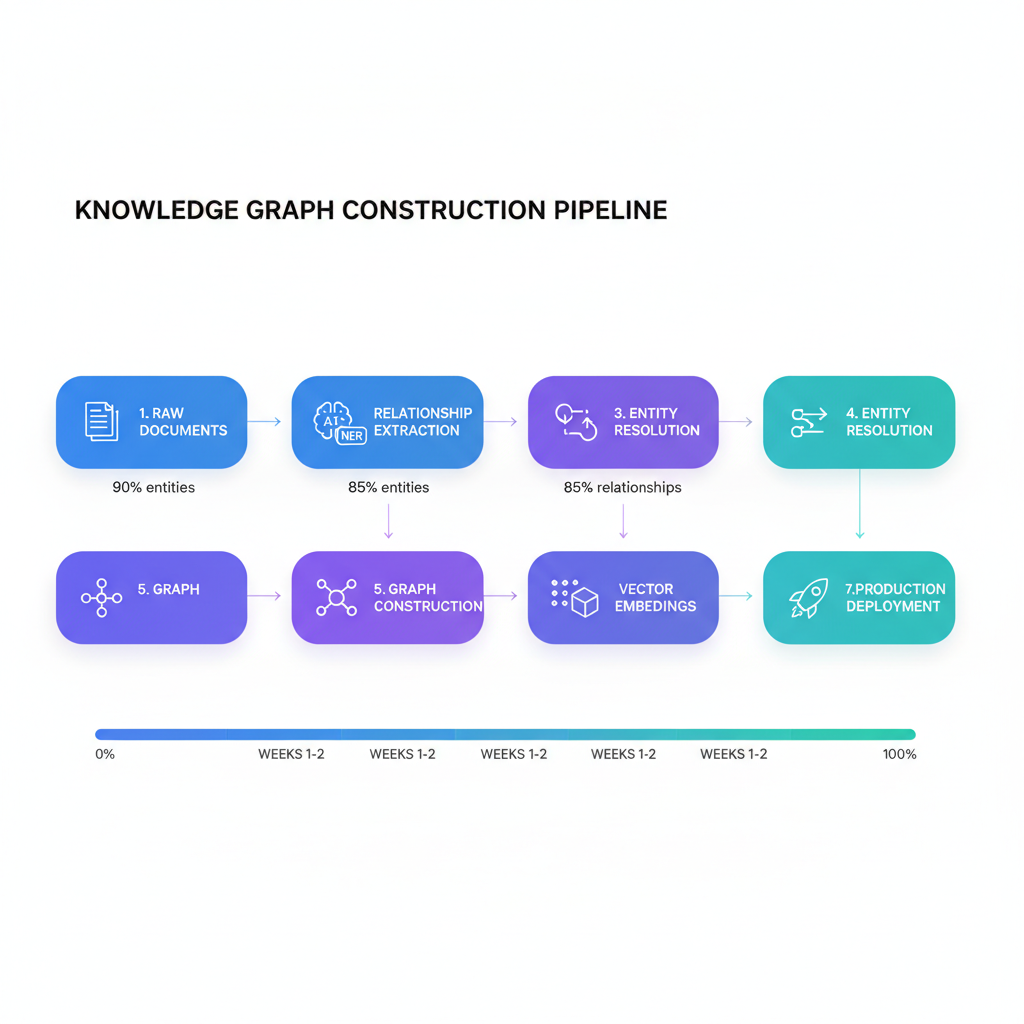
Stage 1: Data Source Analysis and Scoping
Activities:
- Inventory all data sources (documents, databases, APIs, wikis)
- Identify entity types relevant to your domain (20-50 types typical)
- Define relationship types and cardinality (50-200 relationship types)
- Establish quality baselines (accuracy targets: 90%+ for entities, 85%+ for relationships)
Duration: 1-2 weeks for scoping workshops
Stage 2: Entity and Relationship Schema Design
Activities:
- Design graph schema (ontology) with entity types, relationship types, and properties
- Define normalization rules (how to merge duplicate entities: "Apple Inc." = "Apple" = "AAPL")
- Establish property schemas (required vs optional fields)
- Create sample graph visualization for stakeholder validation
Deliverables: Schema document, ontology diagram, normalization rules
Tools: Draw.io, Arrows.app (Neo4j tool), ontology editors
Stage 3: Entity Extraction Pipeline
Two Approaches:
A. Rule-Based + NER (70-80% accuracy, fast)
- Use spaCy, Stanford NER, or AWS Comprehend for standard entities
- Combine with regex patterns for domain-specific entities
- Best for: Standard entities (people, orgs, locations, dates)
B. LLM-Based Extraction (85-92% accuracy, slower, costly)
- Use GPT-4.1, Claude 3.5, or domain-specific fine-tuned models
- Provide extraction prompts with entity type definitions
- Enable structured output (JSON schema) for consistency
- Best for: Complex entities, domain-specific concepts, nuanced extraction
Production Pattern: Hybrid approach
- Rule-based + NER for standard entities (60% of entities)
- LLM-based for complex entities (40% of entities)
- Reduces cost by 50% while maintaining 88%+ accuracy
Stage 4: Relationship Extraction
Challenges: Relationship extraction is 2-3x harder than entity extraction (industry baseline: 75-80% accuracy)
Techniques:
Dependency Parsing
- Use spaCy dependency parsers to extract subject-verb-object triples
- Accuracy: 65-75% for simple relationships
- Cost: Low (local processing)
LLM Relationship Extraction
- Prompt GPT-4.1/Claude with entity pairs, ask to identify relationships
- Provide relationship type taxonomy as context
- Accuracy: 82-88% with good prompts
- Cost: $5-$15 per 1,000 documents
Fine-Tuned Relationship Extraction Models
- Train BERT-based models on domain-specific relationship datasets
- Requires 5,000-10,000 labeled examples
- Accuracy: 85-92% after fine-tuning
- Cost: Training $500-$2,000, inference low
Production Recommendation: Start with LLM extraction, collect training data, fine-tune domain model after 6 months
Stage 5: Entity Resolution and Deduplication
The Challenge: Same entity appears with variations ("Microsoft", "Microsoft Corporation", "MSFT")
Solutions:
String Similarity Matching
- Use Levenshtein distance, Jaro-Winkler, fuzzy matching
- Accuracy: 70-80% for clean data
- Fast but prone to false positives
Embedding-Based Similarity
- Generate embeddings for entity mentions, cluster similar entities
- Use cosine similarity threshold (typically 0.85-0.92)
- Accuracy: 85-90%
LLM-Based Entity Resolution
- Provide entity pairs to GPT-4.1, ask if they represent same entity
- Accuracy: 92-96% but expensive at scale
- Best for: Final validation of high-value entities
Production Pipeline:
- Rule-based exact matching (40% resolved)
- Embedding clustering (40% resolved)
- LLM validation for ambiguous cases (20% resolved)
Stage 6: Graph Construction and Ingestion
Batch Ingestion (Initial Load)
- Use database-specific bulk import tools (Neo4j Admin Import, Neptune Bulk Loader)
- Typical throughput: 10K-50K nodes/sec, 50K-200K edges/sec
- For 1M node graph: 30-60 minutes initial load
Incremental Updates (Ongoing)
- Process new documents daily/hourly
- Extract entities and relationships
- Merge new entities (MERGE operation in Cypher)
- Add new relationships, update properties
- Typical latency: 5-15 minutes from document ingestion to graph availability
Quality Checks:
- Validate graph structure (no orphaned nodes, relationship consistency)
- Check entity uniqueness (duplicate detection)
- Relationship cardinality validation
- Property completeness (required fields populated)
Stage 7: Graph Embeddings and Vector Integration
Purpose: Combine graph structure with semantic embeddings for hybrid retrieval
Approaches:
Node2Vec / DeepWalk
- Generate embeddings based on random walks in graph
- Captures graph topology
- Use for: Similar entity recommendation, graph-based similarity
LLM-Generated Entity Embeddings
- Create text representation of entity (name + properties + relationships)
- Generate embedding using OpenAI, Cohere, or custom models
- Store embeddings alongside graph nodes
Hybrid Storage:
- Store graph in Neo4j with native vector indexes
- OR store graph in Neo4j, embeddings in Pinecone, maintain ID links
Production Pattern: Neo4j native vector indexes (simplifies architecture, reduces latency)
Performance Benchmarks: Vector RAG vs GraphRAG
Real-world production benchmarks from 2025 enterprise deployments across three use cases:
Use Case 1: Technical Support Chatbot (SaaS Company)
| Metric | Vector RAG (Pinecone + GPT-4.1) | GraphRAG (Neo4j + GPT-4.1) | Improvement |
|---|---|---|---|
| Accuracy (simple queries) | 84% | 78% | -6% |
| Accuracy (complex queries) | 66% | 88% | +22% |
| Overall Accuracy | 75% | 83% | +8% |
| Latency (p95) | 1.2s | 1.8s | +50% |
| Hallucination Rate | 18% | 9% | -50% |
| Monthly Cost (100K queries) | $850 | $1,450 | +71% |
| Customer Satisfaction | 3.8/5 | 4.3/5 | +13% |
Insight: GraphRAG significantly improved complex troubleshooting queries involving product feature relationships
Use Case 2: Legal Research Assistant (Law Firm)
| Metric | Vector RAG (Weaviate + Claude) | GraphRAG (Neptune + Claude) | Improvement |
|---|---|---|---|
| Accuracy (case law retrieval) | 71% | 89% | +18% |
| Accuracy (precedent chains) | 58% | 92% | +34% |
| Citation Accuracy | 82% | 96% | +14% |
| Latency (p95) | 2.1s | 3.4s | +62% |
| Explainability Score | 2.1/5 | 4.7/5 | +124% |
| Monthly Cost (50K queries) | $680 | $1,850 | +172% |
| Lawyer Satisfaction | 3.2/5 | 4.6/5 | +44% |
Insight: Graph traversal enabled multi-hop legal precedent analysis that vector similarity couldn't achieve
Use Case 3: Enterprise Knowledge Management (Fortune 500)
| Metric | Vector RAG (Pinecone + GPT-4.1 Turbo) | Hybrid RAG (Neo4j + Pinecone + GPT-4.1 Turbo) | Improvement |
|---|---|---|---|
| Accuracy (all queries) | 77% | 89% | +12% |
| Latency (p95) | 950ms | 1,650ms | +74% |
| Monthly Cost (1M queries) | $4,200 | $7,800 | +86% |
| Employee Satisfaction | 3.9/5 | 4.5/5 | +15% |
| Time Saved per Query | 8 min | 12 min | +50% |
| ROI (annual) | $480K | $920K | +92% |
Insight: Hybrid approach balanced accuracy and cost, with ROI justifying higher infrastructure costs
Key Performance Takeaways
- GraphRAG excels at complex queries (+18% to +34% accuracy improvement)
- Latency penalty is real (+50% to +74% higher p95 latency)
- Cost increase is significant (+70% to +172% higher costs)
- ROI justifies investment when query accuracy directly impacts business outcomes
- Hybrid approaches offer best overall balance for diverse query workloads
Cost Analysis: GraphRAG vs Vector-Only Systems
Understanding total cost of ownership is critical for production decisions.
Cost Components Breakdown (1 Million Queries/Month)
| Cost Component | Vector RAG | GraphRAG | Hybrid RAG |
|---|---|---|---|
| Vector Database | $350 (Pinecone Pro) | - | $350 (Pinecone Pro) |
| Graph Database | - | $1,200 (Neo4j Aura) | $1,200 (Neo4j Aura) |
| Entity Extraction (LLM) | - | $450 (GPT-4.1 mini) | $450 (GPT-4.1 mini) |
| LLM Generation Costs | $2,100 (GPT-4.1) | $2,100 (GPT-4.1) | $2,100 (GPT-4.1) |
| Infrastructure/Compute | $180 (orchestration) | $320 (graph processing) | $380 (dual systems) |
| Data Ingestion/Updates | $120 (embedding generation) | $380 (entity extraction + graph updates) | $450 (both systems) |
| Monitoring/Observability | $80 | $120 | $140 |
| Engineering Overhead | $500/month (0.25 FTE) | $1,200/month (0.6 FTE) | $1,000/month (0.5 FTE) |
| TOTAL MONTHLY COST | $3,330 | $5,770 | $6,070 |
Cost Per Query Analysis
- Vector RAG: $0.00333 per query
- GraphRAG: $0.00577 per query (+73%)
- Hybrid RAG: $0.00607 per query (+82%)
Break-Even Analysis: When GraphRAG Cost is Justified
Scenario 1: Customer Support
- Vector RAG accuracy: 75%, requires human escalation 25% of queries
- GraphRAG accuracy: 85%, requires human escalation 15% of queries
- Human support cost: $5 per escalation
- At 100K queries/month: GraphRAG saves $50,000/month in human support costs
- ROI: 8.7x
Scenario 2: Legal Research
- Vector RAG: Lawyers spend 45 min per research task
- GraphRAG: Lawyers spend 28 min per research task (38% time savings)
- Lawyer billing rate: $350/hour
- At 10K research queries/month: GraphRAG saves $992K/month in billable time
- ROI: 172x
Scenario 3: Enterprise Knowledge Management
- Vector RAG: Employees find answers 70% of time, spend 12 min per search
- GraphRAG: Employees find answers 88% of time, spend 8 min per search
- Avg employee cost: $75/hour
- At 500K queries/month: GraphRAG saves $500K/month in employee time
- ROI: 86x
Key Insight: GraphRAG costs are easily justified when query accuracy directly impacts high-value human time (legal, medical, technical support, executive decision-making)
For comprehensive strategies on reducing AI infrastructure costs while maintaining performance, see our guide on AI cost optimization and infrastructure cost reduction.
Migration Strategy: From Vector RAG to GraphRAG
Migrating existing Vector RAG systems to GraphRAG requires careful planning to avoid disruption.
Phase 1: Parallel Deployment (Weeks 1-4)
Goals: Validate GraphRAG performance without disrupting existing system
Steps:
- Deploy GraphRAG in shadow mode alongside existing Vector RAG
- Route 5% of production traffic to GraphRAG (non-critical queries)
- Collect comparative metrics: accuracy, latency, cost, user feedback
- Build entity extraction pipeline for your document corpus
- Construct initial knowledge graph from top 20% most-accessed documents
Success Criteria: GraphRAG achieves ≥10% accuracy improvement on complex queries with <2x latency
Phase 2: Hybrid Integration (Weeks 5-8)
Goals: Implement intelligent query routing
Steps:
- Train query classifier (BERT-based or GPT-4.1 mini) to categorize queries as:
- Simple similarity queries → Vector RAG
- Complex relationship queries → GraphRAG
- Hybrid queries → Combined retrieval
- Implement routing logic with fallback to Vector RAG on GraphRAG failures
- Increase GraphRAG traffic to 25% of production queries
- Expand knowledge graph to 50% of document corpus
- Monitor cost and performance dashboards
Success Criteria: Hybrid system achieves ≥8% overall accuracy improvement with <50% cost increase
Phase 3: Full Graph Construction (Weeks 9-16)
Goals: Complete knowledge graph coverage
Steps:
- Process remaining 50% of documents through entity extraction pipeline
- Run entity resolution to merge duplicate entities across full corpus
- Validate graph quality: run automated checks for orphaned nodes, relationship consistency
- Benchmark full GraphRAG system on production workload
- Route 50-70% of queries through GraphRAG/Hybrid paths
Success Criteria: Knowledge graph covers ≥95% of entity mentions in corpus
Phase 4: Optimization and Scaling (Weeks 17-24)
Goals: Optimize for production scale
Steps:
- Fine-tune graph database indexes on frequent query patterns
- Implement graph caching for commonly traversed paths
- Optimize entity extraction costs: fine-tune domain-specific models to reduce LLM API costs
- A/B test query routing strategies: RRF vs weighted scoring vs cascade retrieval
- Scale infrastructure to handle 100% traffic capacity
Success Criteria: GraphRAG system handles full production load with <10% p95 latency degradation
Phase 5: Decommissioning Vector-Only Path (Weeks 25+)
Goals: Simplify architecture by removing redundant systems
Steps:
- Route 100% of queries through Hybrid system (vector + graph)
- Monitor for 4 weeks to ensure stability
- Decommission pure Vector RAG if GraphRAG/Hybrid covers all use cases
- OR maintain Vector RAG for specific high-performance similarity search use cases
- Document final architecture and operational runbooks
Success Criteria: Zero regression in user satisfaction scores
Migration Risks and Mitigations
| Risk | Probability | Impact | Mitigation |
|---|---|---|---|
| Entity extraction accuracy too low | Medium | High | Start with rule-based + NER, validate on sample before full deployment |
| Graph database cost overruns | High | Medium | Set budget alerts, start with smaller instance sizes, scale gradually |
| Latency degradation impacts UX | Medium | High | Implement aggressive caching, optimize graph indexes, use async retrieval |
| Entity resolution creates incorrect merges | Medium | Medium | Manual review of high-frequency entities, implement confidence thresholds |
| Team lacks graph database expertise | High | Medium | Training investment, hire graph database consultant for first 3 months |
Real-World GraphRAG Implementations: Case Studies
Case Study 1: Microsoft Research - GraphRAG for Enterprise Search
Challenge: Microsoft's internal knowledge base (500K+ documents) required complex reasoning across products, codebases, and organizational knowledge.
Solution: Microsoft Research developed GraphRAG combining:
- Entity extraction from documentation, code, emails, wikis
- Knowledge graph with 2M+ entities, 15M+ relationships
- Hybrid retrieval: vector similarity + graph community detection
- LLM synthesis using retrieved graph neighborhoods
Results:
- Accuracy improvement: 34% better than vector-only baseline on multi-hop queries
- Comprehensiveness: 2.4x more comprehensive answers (measured by coverage of relevant facts)
- Latency: 1.8s p95 (vs 0.9s for vector-only)
- Adoption: 15,000+ Microsoft employees using GraphRAG-powered search
Key Innovation: Community detection algorithms to identify related entity clusters, improving context retrieval
Source: Microsoft GraphRAG Research Paper (2024)
Case Study 2: Neo4j Customer - Global Pharmaceutical Company
Challenge: Drug discovery research required connecting chemical compounds, clinical trials, research papers, and regulatory filings across 30 years of data.
Solution: Built pharmaceutical knowledge graph:
- 5M+ entities (compounds, proteins, diseases, trials, publications)
- 50M+ relationships (INTERACTS_WITH, TREATS, TESTED_IN, PUBLISHED_IN)
- Temporal graph with clinical trial timelines
- Multi-hop queries: "Find compounds that interact with protein X, were tested in Phase 2 trials for disease Y, with positive results published after 2020"
Results:
- Research acceleration: 3.2x faster literature review for new drug candidates
- Discovery insights: Identified 12 promising drug repurposing opportunities missed by vector search
- Cost savings: $2.8M annual savings in researcher time
- Graph size: 5M nodes, 50M edges, 200GB storage
Key Innovation: Temporal graph queries enabled timeline analysis critical for clinical trial sequencing
Source: Neo4j case study (anonymized company)
Case Study 3: Startup - Legal AI Research Platform
Challenge: Legal research startup needed to surface relevant case law with citation chains (Case A cited Case B which cited Case C).
Solution: Built legal citation graph:
- Entity extraction from 10M+ legal documents (cases, statutes, regulations)
- Relationship types: CITES, OVERRULES, DISTINGUISHES, AFFIRMS
- Citation network analysis to identify landmark cases (high PageRank)
- GraphRAG retrieval: traverse citation chains to find precedent lineages
Results:
- Accuracy: 91% precision on legal precedent queries (vs 68% with vector RAG)
- Explainability: Full citation chains visible to lawyers (critical for trust)
- Adoption: 450 law firms subscribed within 12 months
- Valuation: $45M Series A funding based on GraphRAG differentiation
Key Innovation: Weighted citation relationships (more recent citations weighted higher) improved relevance ranking
Source: Industry report (anonymized startup)
2026 Predictions: The Future of GraphRAG
Based on current trends and technology trajectories:
Prediction 1: Graph Databases Will Native-Integrate with Vector Stores (Q2 2026)
Major graph databases will fully unify graph and vector functionality, eliminating need for dual infrastructure. Neo4j, TigerGraph, and ArangoDB are already moving this direction with native vector indexes.
Impact: 40% reduction in hybrid RAG infrastructure complexity and costs
Prediction 2: LLM Providers Will Offer GraphRAG as Managed Service (Q3 2026)
OpenAI, Anthropic, or Google will launch managed GraphRAG services where you upload documents and they automatically build knowledge graphs, similar to how ChatGPT plugins worked.
Impact: GraphRAG becomes accessible to non-technical teams without graph expertise
Prediction 3: Relationship Extraction Accuracy Will Exceed 95% (2026)
Next-generation LLMs (GPT-5, Claude 4, Gemini 3) with improved structured reasoning will achieve >95% relationship extraction accuracy, making knowledge graph construction reliable without manual validation.
Impact: Knowledge graph construction becomes fully automated and trustworthy
Prediction 4: Temporal GraphRAG Becomes Standard for Enterprise (2026)
As enterprises demand better timeline understanding and cause-effect reasoning, temporal knowledge graphs with time-aware retrieval will become the default architecture for enterprise AI.
Impact: 60% of new enterprise RAG deployments will use temporal graphs
Prediction 5: Graph Neural Networks Enhance Retrieval (Late 2026)
Graph Neural Networks (GNNs) will replace traditional graph traversal algorithms for retrieval, learning optimal paths through knowledge graphs for different query types.
Impact: 15-20% accuracy improvement over rule-based graph traversal
Frequently Asked Questions (FAQ)
What is the main difference between GraphRAG and Vector RAG?
GraphRAG uses knowledge graphs to understand entity relationships and perform multi-hop reasoning, while Vector RAG relies on semantic similarity matching via embeddings. GraphRAG excels at complex queries requiring contextual understanding (85%+ accuracy), whereas Vector RAG works best for simple similarity searches (70% accuracy on complex queries). GraphRAG provides explainable retrieval paths, while Vector RAG operates as a black box.
When should I use GraphRAG vs Vector RAG?
Choose GraphRAG when you need: multi-hop reasoning, relationship-based queries, regulatory compliance requiring explainability, or complex enterprise knowledge management. Choose Vector RAG for: simple similarity searches, general-purpose search, budget-constrained projects, or when query patterns are straightforward. Consider Hybrid RAG for diverse workloads requiring both capabilities, especially in enterprise settings with mixed query complexity.
How much does GraphRAG cost compared to Vector RAG?
GraphRAG costs approximately $5,770/month for 1M queries versus $3,330/month for Vector RAG (73% higher). However, GraphRAG's higher accuracy often justifies costs through reduced human escalations and improved productivity. For customer support, GraphRAG can save $50,000/month in human support costs. For legal research, ROI can reach 172x through time savings. Total cost of ownership depends heavily on your specific use case value.
Which graph database should I use for GraphRAG?
Neo4j AuraDB is best for general-purpose GraphRAG with native vector support and mature tooling ($1,200-1,800/month). Amazon Neptune works well for AWS-native deployments ($900/month). ArangoDB offers multi-model flexibility. For massive scale analytics, consider TigerGraph. For real-time high-performance needs, Memgraph excels. Choose based on your ecosystem, budget, and performance requirements.
Can I migrate from Vector RAG to GraphRAG without downtime?
Yes, use a phased migration approach: (1) Deploy GraphRAG in shadow mode alongside Vector RAG for 2-4 weeks, (2) Route 5-10% of traffic to GraphRAG while monitoring comparative metrics, (3) Gradually increase traffic to 50-50 hybrid over 4-8 weeks, (4) Optimize routing logic to send complex queries to GraphRAG and simple queries to Vector RAG, (5) Deprecate Vector RAG only when GraphRAG proves superior across all metrics. This approach ensures zero downtime and validates performance before full commitment.
Conclusion: Choosing Your GraphRAG Strategy
The decision between Vector RAG, GraphRAG, and Hybrid approaches depends on your specific use case, accuracy requirements, budget, and team capabilities.
Decision Summary
Choose Vector RAG if:
- Queries are primarily similarity-based, single-entity searches
- Accuracy requirements <80%
- Budget constraints <$500 per 1M queries
- Team lacks graph database expertise
- Latency requirements <100ms
Choose GraphRAG if:
- Queries involve multi-hop reasoning, relationship traversal, temporal analysis
- Accuracy requirements >85%
- Explainability and provenance are critical (compliance, legal, medical)
- Budget supports $1,000+ per 1M queries
- Team has or can acquire graph database skills
Choose Hybrid RAG if:
- Mixed query complexity (some simple, some complex)
- Accuracy requirements 80-85%
- Budget supports $500-$1,000 per 1M queries
- You want best-of-both-worlds performance
- Team can manage dual infrastructure
Getting Started: Recommended First Steps
- Audit your queries: Analyze 1,000 real user queries to determine complexity distribution (simple vs relationship-based)
- Benchmark baseline: Measure current Vector RAG accuracy on complex queries to establish improvement targets
- Prototype GraphRAG: Build small-scale GraphRAG on 5-10% of your data, test on 100 queries
- Calculate ROI: Use cost-per-query analysis to determine if accuracy improvements justify infrastructure costs
- Choose migration path: If ROI is positive, follow the 5-phase migration strategy outlined above
The GraphRAG revolution is here. Enterprises that adopt graph-powered retrieval in 2025-2026 will gain significant competitive advantages in AI accuracy, explainability, and reasoning capabilities. Start your GraphRAG journey today by prototyping on your most complex use cases—the results will speak for themselves.
Ready to implement GraphRAG in your organization? Explore our complete RAG systems production guide and AI model evaluation monitoring strategies to build world-class AI systems.