

Transformer models have revolutionized the field of natural language processing (NLP) with their powerful self-attention mechanism. In this guide, we’ll dive into the implementation of transformer models in NLP using Python. We’ll cover the key concepts behind transformers and walk through a simple example code to help you get started.
What are Transformers?
A Transformer is a neural network architecture that was introduced in 2017 by Vaswani et al. in their paper “Attention is All You Need.” The key innovation of the Transformer is its self-attention mechanism, which allows the model to consider all words in a sentence simultaneously, instead of one word at a time like traditional recurrent neural networks (RNNs) or convolutional neural networks (CNNs). This self-attention mechanism is what makes Transformers so effective for NLP tasks, as it allows the model to capture complex relationships between words and sentences.
How do Transformers Work?
Transformers consist of an encoder and a decoder, which work together to perform NLP tasks. The encoder processes the input sequence, generating hidden representations of each word in the sequence. The decoder then uses these hidden representations to generate an output sequence.
One of the key components of the Transformer architecture is the self-attention mechanism, which allows the model to consider all words in the input sequence at once. The self-attention mechanism works by first computing a set of attention scores for each word in the sequence, indicating how important each word is in relation to the others. The model then uses these attention scores to compute a weighted sum of the hidden representations of all words, effectively “focusing” on the most relevant parts of the input sequence.
Why are Transformers so Revolutionary?
Before the introduction of the Transformer architecture, NLP models were mostly based on RNNs or CNNs. However, RNNs have the limitation that they process one word at a time and struggle to capture long-term dependencies in the input sequence, while CNNs are designed for image processing and are not well-suited to NLP tasks.Transformers, on the other hand, overcome these limitations thanks to their self-attention mechanism. By allowing the model to consider all words in a sequence at once, Transformers can capture complex relationships between words and sentences, leading to much better performance on NLP tasks. Additionally, Transformers are also highly parallelizable, meaning they can be trained much faster than traditional NLP models, making them a valuable tool for NLP research and applications.
Transformer Architecture Diagram
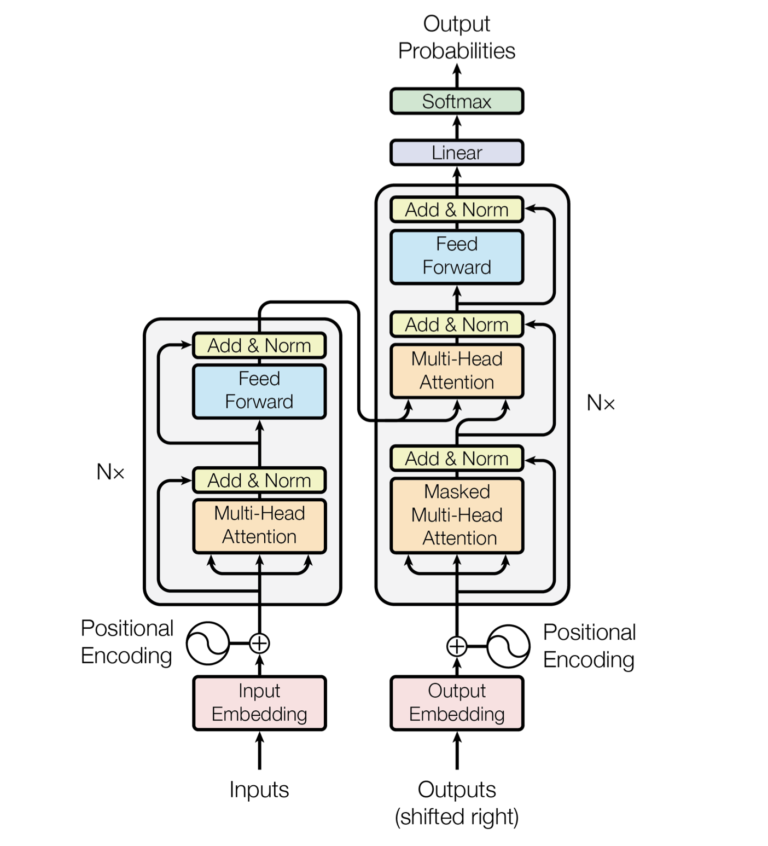
Coding Example
Let’s implement a simple Transformer architecture in PyTorch to get a better understanding of how it works. In this example, we’ll train a Transformer to predict the next word in a sentence given the previous words.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, dim_feedforward, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.encoder_layer = nn.TransformerEncoderLayer(d_model, num_heads, dim_feedforward)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=1)
self.fc = nn.Linear(d_model, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.embedding(x)
x = self.transformer_encoder(x)
x = x.permute(0, 2, 1)
x = self.fc(x)
return x
In the forward method, we first pass the input x through an embedding layer to generate dense word representations. Then, we pass the embedded input through the Transformer encoder, which performs the self-attention mechanism and generates hidden representations for each word in the input sequence. Finally, we use a linear layer to generate the output probabilities for each word in the vocabulary.
To train the Transformer, we’ll use the negative log likelihood loss and the Adam optimizer.
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
#Training Loop
for epoch in range(num_epochs):
for i, (x, y) in enumerate(training_data):
optimizer.zero_grad()
output = model(x)
loss = criterion(output.view(-1, vocab_size), y.view(-1))
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(“Epoch: [{}/{}], Loss: {:.4f}”.format(epoch+1, num_epochs, loss.item()))
In this example, we loop over the training data, generate the output for each batch, calculate the loss, and perform backpropagation to update the model parameters. This is just a simple example to demonstrate the basic structure of a Transformer architecture. In a real-world NLP task, you would use a much larger model with many more layers and heads and train it on a massive corpus of text data.
You can refer to the original paper in the link: https://arxiv.org/pdf/1706.03762.pdf)%20for%20more%20details
Conclusion
Transformers have revolutionized the field of NLP, leading to significant improvements in performance on various NLP tasks. The key innovation behind Transformers is their self-attention mechanism, which allows the model to consider all the words in a sentence simultaneously and capture complex relationships between words and sentences. With their high parallelizability, Transformers have become a popular tool for NLP research and applications, and we can expect to see even more advances in NLP in the coming years.
Related Post
How to Impress a Girlfriend: https://iterathon.tech//how-to-impress-a-girlfriend-using-python/
Random Password Generator in Python: https://iterathon.tech//random-password-generator-in-python/
LEARN SOMETHING NEW ❤️