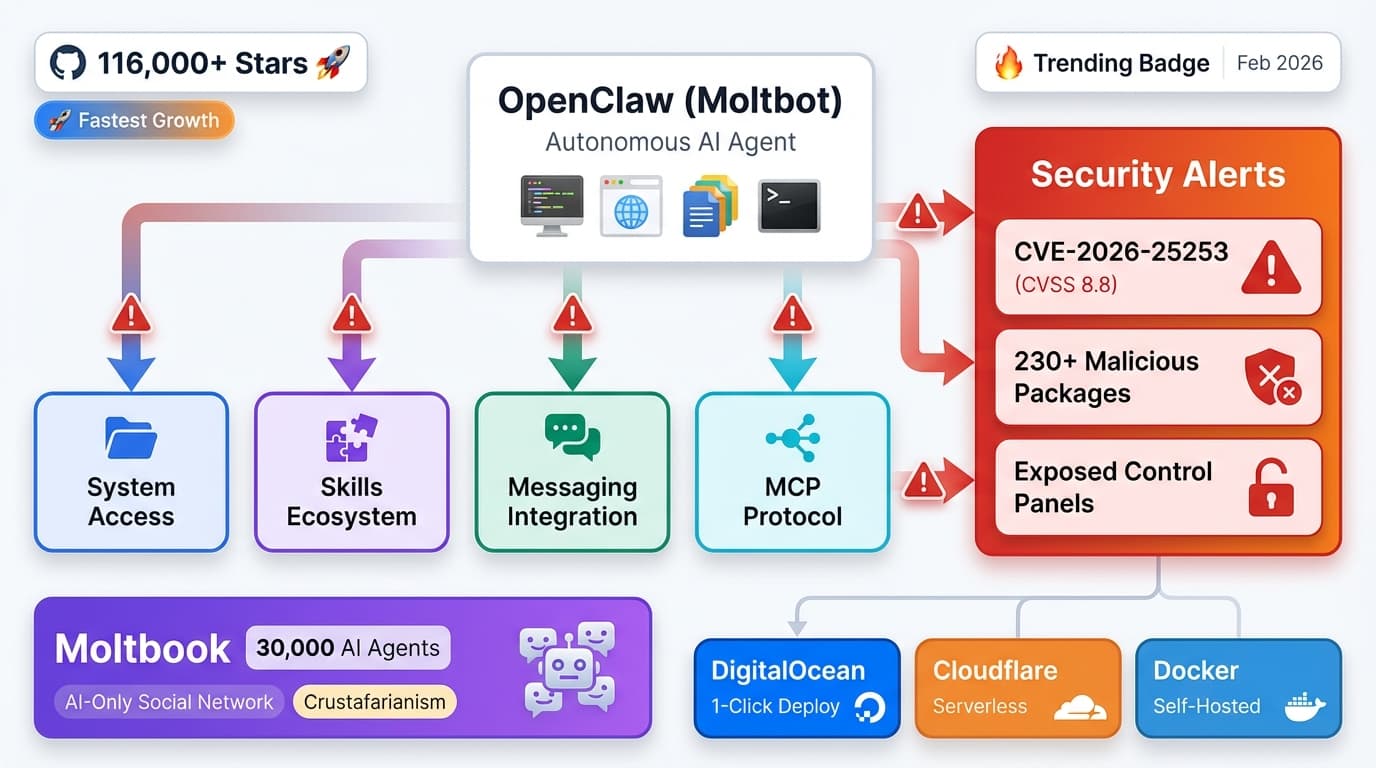
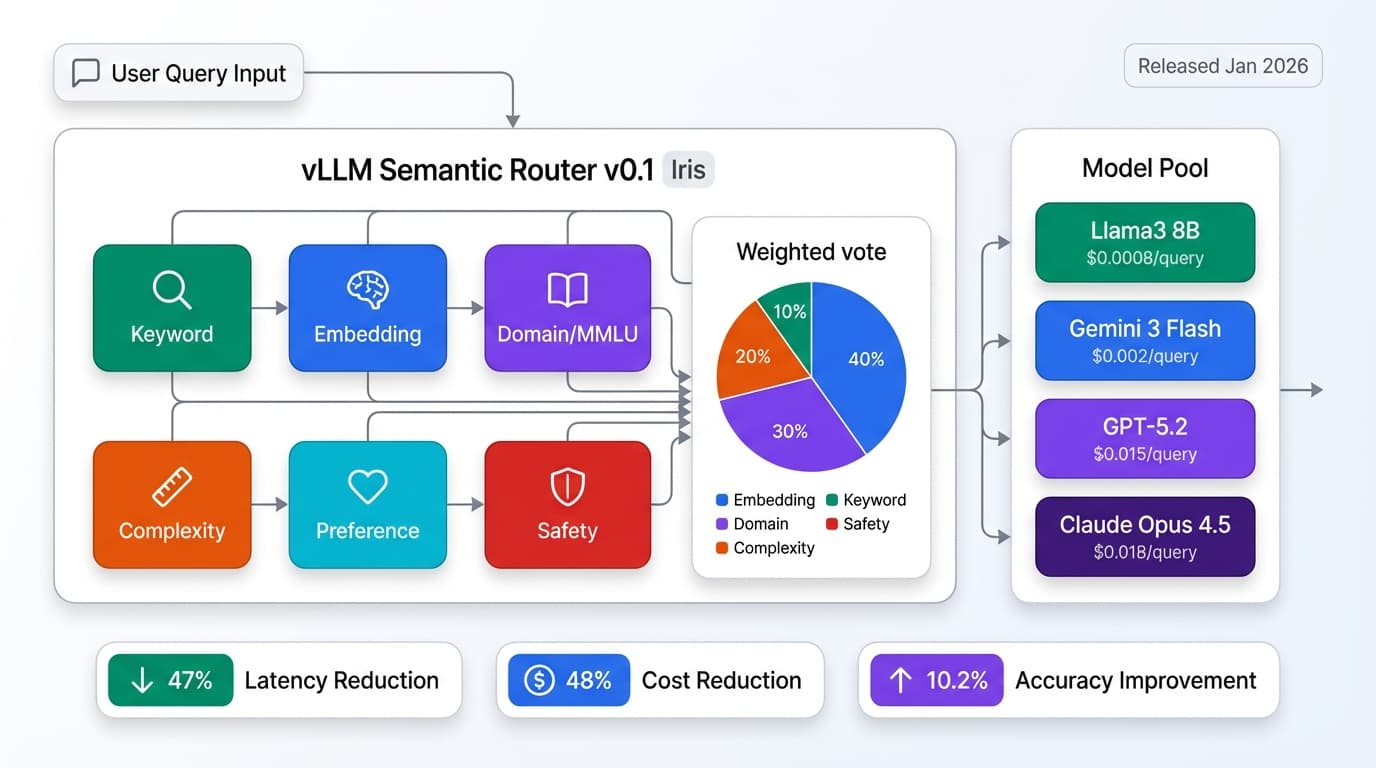
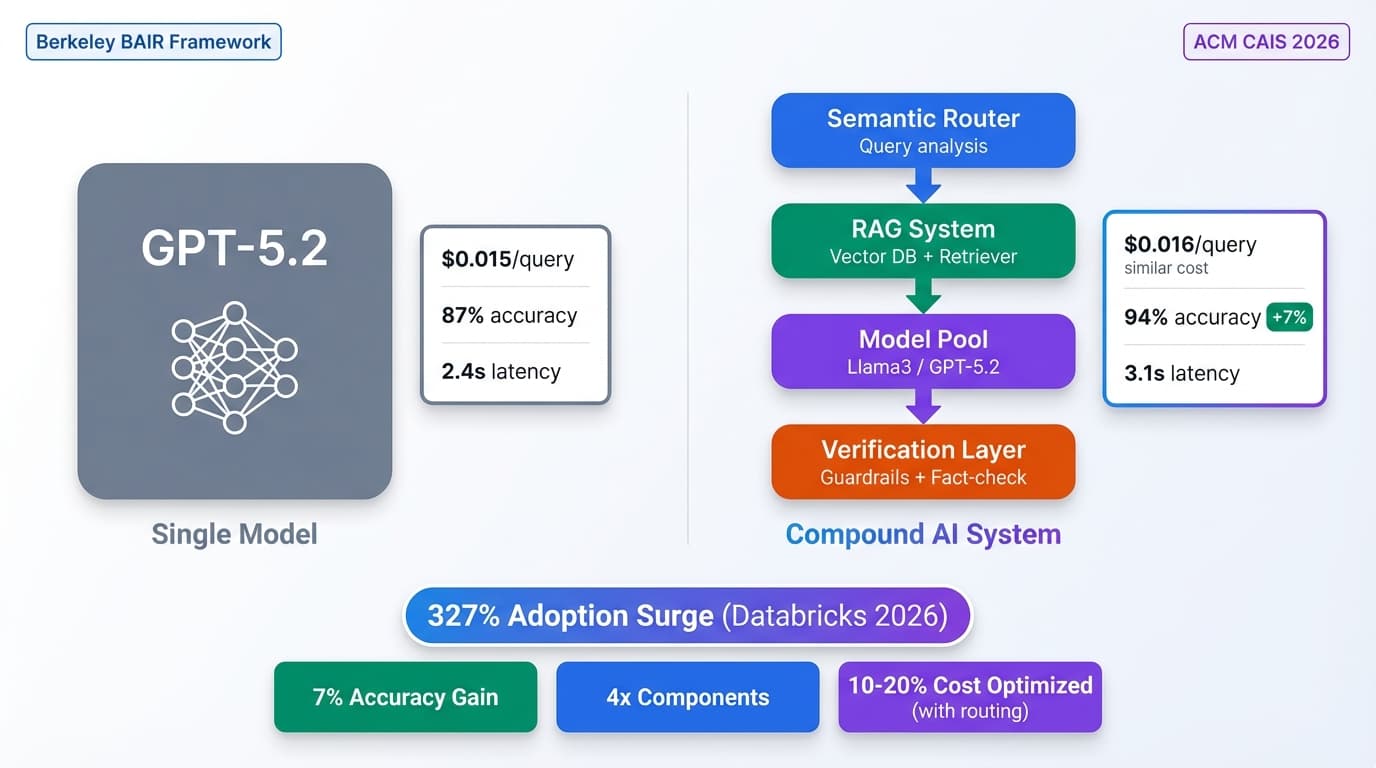
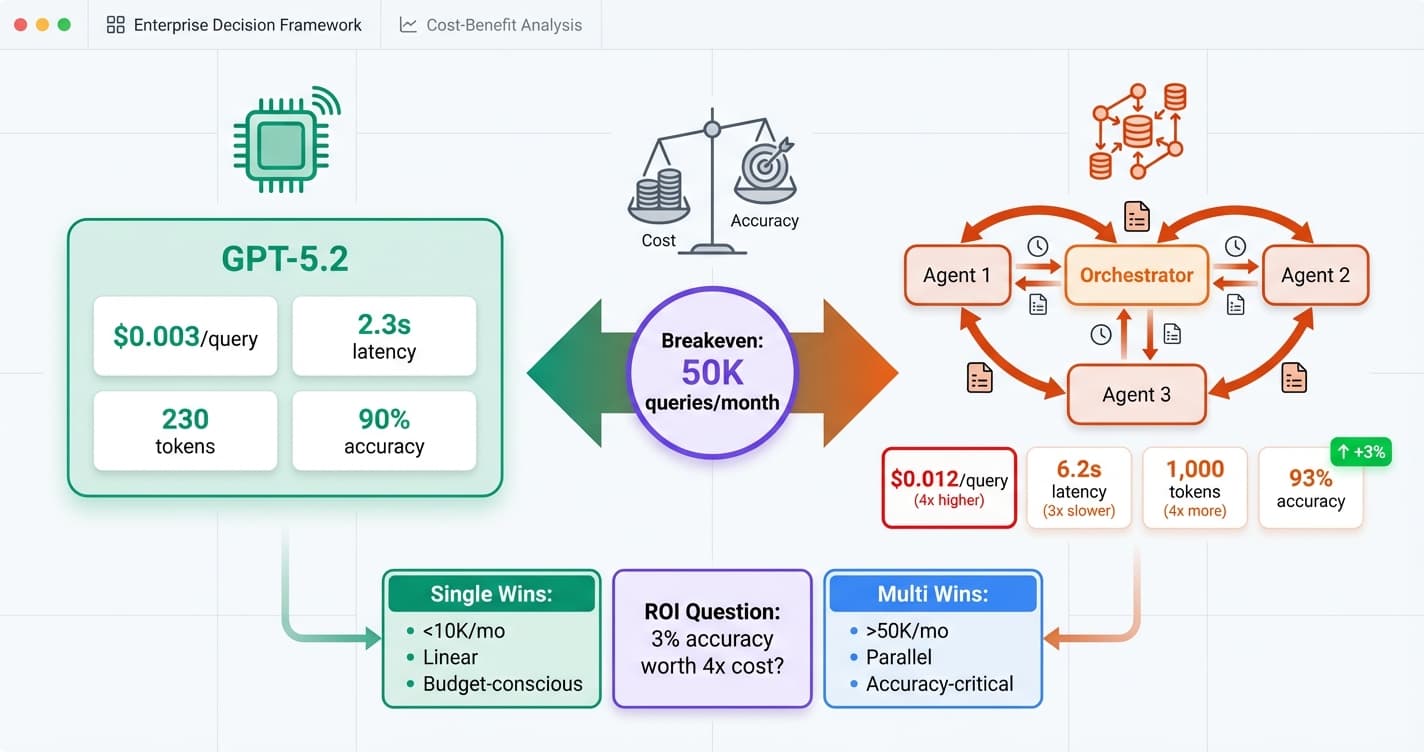
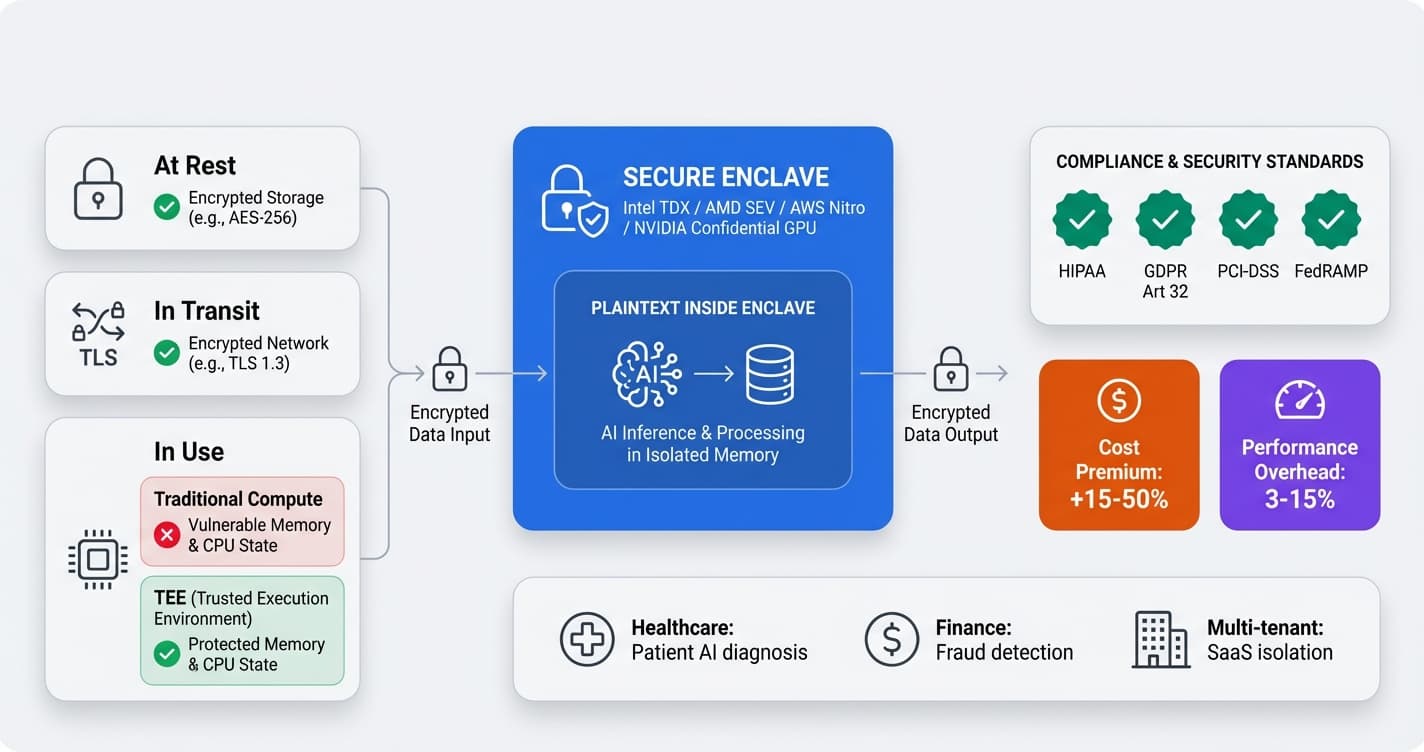
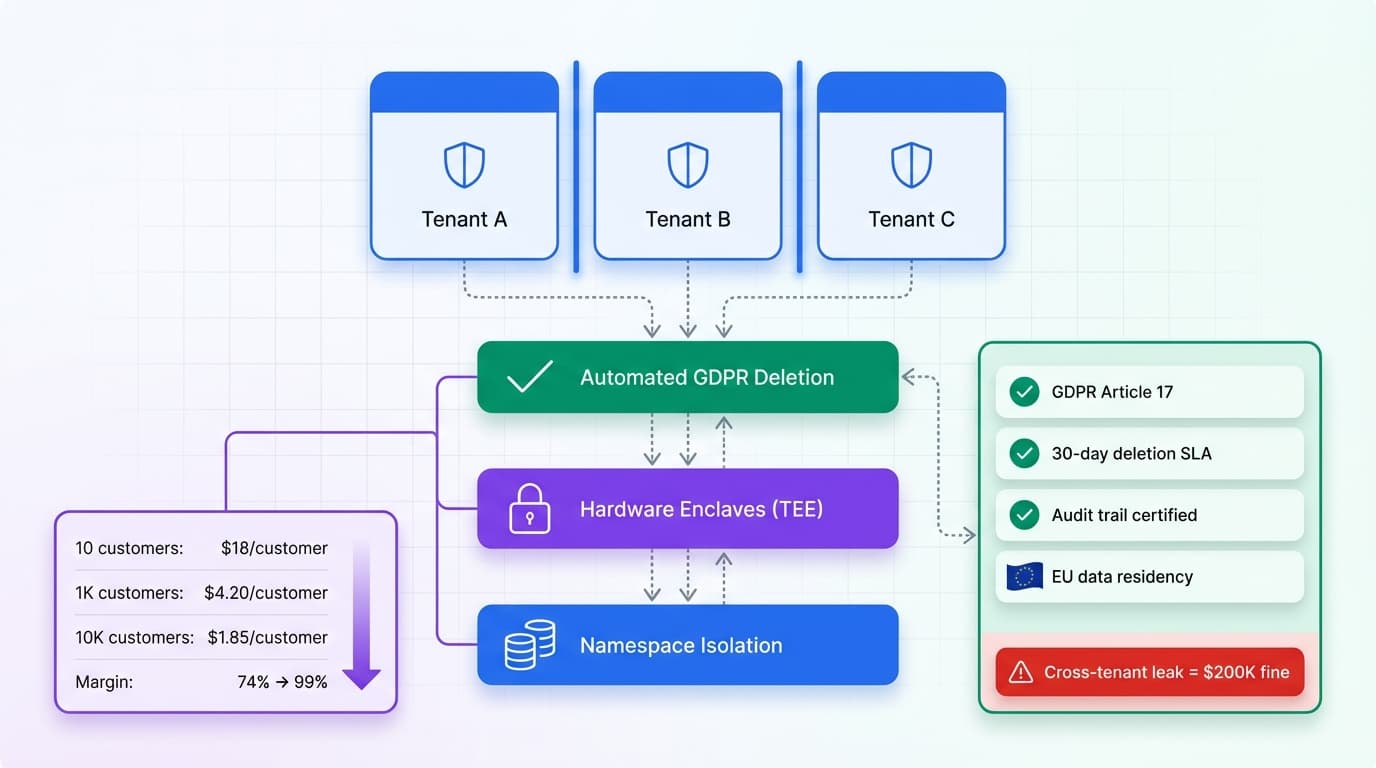
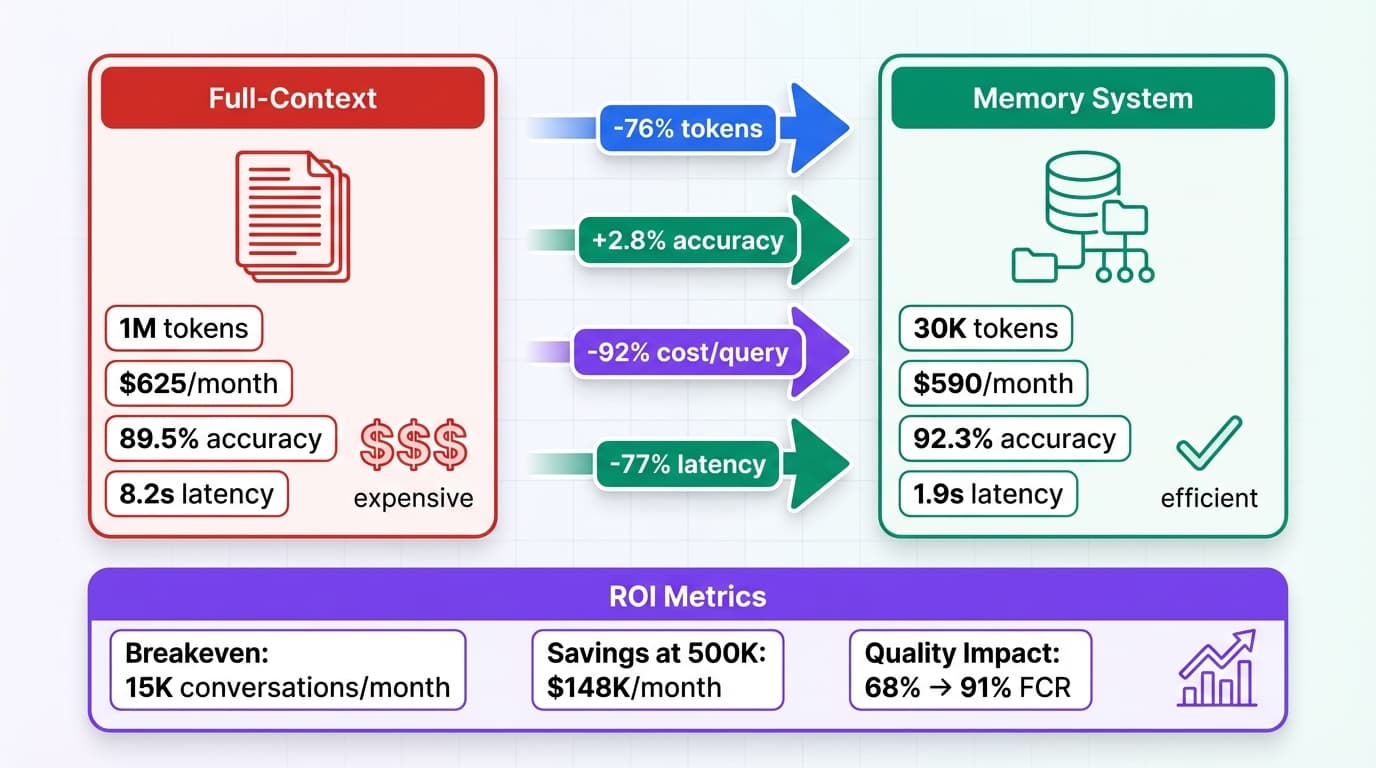
AI in Production
How to Build Real-Time ML Feature Pipelines Production 2026
Build production real-time ML feature pipelines with Kafka and Flink. Achieve sub-40ms latency, solve training-serving skew, and deploy streaming feature stores at scale.
•13 min read